3 minutes
More Python Fiddlework
Recently I came across a wonderful YouTube Channel, Arjan Codes, and I have already learned a great deal from many of his videos, tutorials, etc. (In particular, I found his video on the use of type hinting in Python to be incredibly helpful, and I have already started to implement some of his suggestions in my own code.) Wanting to just try it out I figured I would put a pretty simple snippet of code that is part of my ever-continuing enjoyment of working with our Canvas LMS solely through the API—trying never to open a web browser. :) With that in mind, how about some code to download all of the submissions for a particular assignment in a course? (It’s getting close to mid-term time, so those’ll be flooding in soon enough … ) I’ve also been having tons of fun lately trying to write code from scratch to do things natively available in the LMS … this is perhaps another prime example of that.
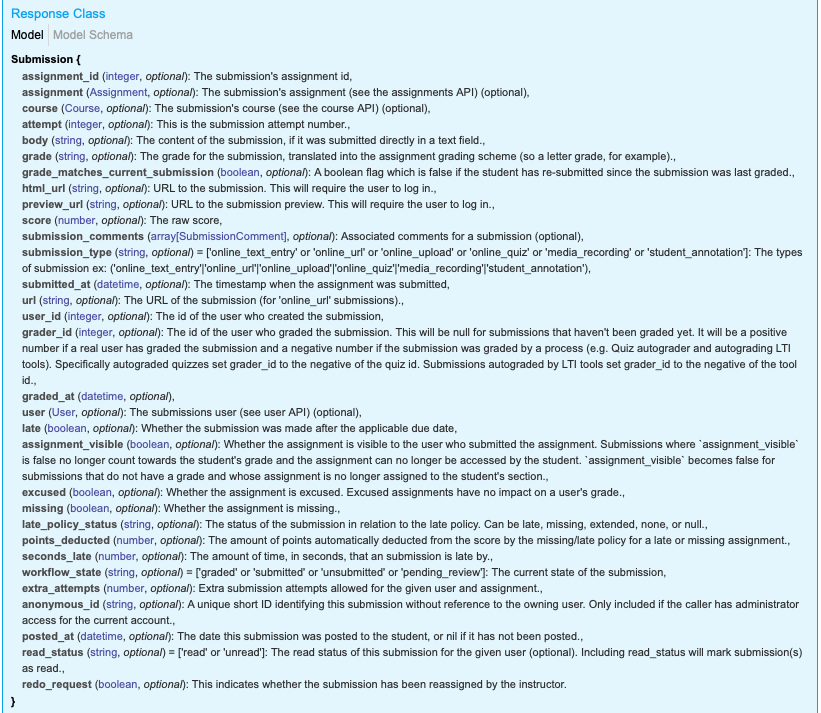
First thing—with our course id and assignment id in hand—we can head over to the Submission endpoint of the API, grab all the submissions, and traverse the returned dictionary for the “html_url” key, which contains the link to the actual submitted file. The full schema as per the API …:
def get_download_links_from_canvas_api(course_id: int, assignment_id: int, user_id: int) -> list:
URL = # URL for the Canvas API Submission endpoint
try:
response = requests.get(URL, headers=header_argument, timeout=15)
response.raise_for_status() # This will raise an HTTPError if the HTTP request returned an unsuccessful status code
data = response.json()
download_links = [attachment['url'] for attachment in data.get('attachments', [])]
if not download_links:
print(f"No download links found for {user_id}")
except requests.exceptions.Timeout as e:
print(f"Request timed out: {e}")
download_links = []
except requests.exceptions.HTTPError as e:
print(f"HTTP error occurred: {e}")
download_links = []
except Exception as e:
print(f"An error occurred: {e}")
download_links = []
return download_links
With all the links in hand, we can then write a function to download the files from the API right onto one’s local machine.
def download_files_from_canvasapi(url: str, header_argument: dict) -> None:
response = requests.get(url, headers=header_argument, timeout=15)
if response.status_code == 200:
content_disposition = response.headers.get('content-disposition')
if content_disposition:
match = re.search('filename="(.+)"', content_disposition)
if match:
filename = match.group(1)
else:
filename = 'downloaded_file'
else:
filename = 'downloaded_file'
with open(filename, 'wb') as file:
file.write(response.content)
print(f'File downloaded successfully as {filename}')
else:
print('Failed to download the file from {url}')
That’s pretty much all we need—in addition to a list of student id numbers, of course. I keep those in a separate json file so I can pretty just tweak a couple of values for each course and then run the script:
import os
API_KEY = # Your Canvas API key goes here
COURSE_ID = # Canvas Course ID goes here
ASSIGNMENT_ID = # Canvas Assignment ID goes here
DOWNLOAD_DIRECTORY = # Path to where you want the downloaded submissions to go
# Opening the list of student_id numbers from a json file
with open('student_ids.json', 'r') as file:
student_list = json.load(file)
student_ids = [student['id'] for student in student_list]
os.makedirs(DOWNLOAD_DIRECTORY, exist_ok=True)
for student_id in student_ids:
download_links = get_download_links_from_canvas_api(COURSE_ID, ASSIGNMENT_ID, student_id)
for download_link in download_links:
download_files_from_canvasapi(download_link, DOWNLOAD_DIRECTORY)
Easy breezy—and far fewer clicks now than the old way of doing things.
API apis python requests python functions from scratch Canvas Instructure Canvas Instructure API writing functions type hinting
531 Words
2023-09-21 00:01