5 minutes
Hemingway (continued)
In my last post, I shared some really simple text classification work on Hemingway, Fitzgerald, and Steinbeck. It was only after posting it that I noticed that Justin Rice beat me to the punch with his post “What Makes Hemingway Hemingway?” over on “The LitCharts Blog”. What was terribly curious to me was that Rice showcases some of the key characteristics that one thinks “makes Hemingway Hemingway”—sentence length, word length, lexical richness, dialogue proportion, parts of speech, characteristic words, and much more. However, I found the plot concerning Hemingway’s use of different “parts of speech” to be quite intriguing, as that plot only utilized some of the most basic parts of speech: adjectives, adverbs, nouns, pronouns, and verbs.
Rice’s post doesn’t link to any code or repo (not a criticism, just something to note before I proffer some additional code/plots of my own here), but it would seem that the “parts of speech,” obviously, doesn’t utilize all of the possibilities for POS tagging and parsing. Also, it seems to me that it might be interesting to see if we could produce some graphs that utilized some of the “extended POS tags” that are available through a library like spaCy. If we utilize all of the POS tags on a Hemingway workj, what would we see—and what would we see when we compared it with something of Fitzgerald’s? Well, I grabbed a copy of The Great Gatsby along with The Sun Also Rises and turned the spaCy on it. (The key Jupyter notebook for this grammatical analysis is available here.)
Let’s show it. As usual, importing libraries and getting our text files read in (as per standard operating procedure, all code for this post is available in the following repository):
import matplotlib.pyplot as plt
import pandas as pd
import spacy
nlp = spacy.load('en_core_web_lg')
with open(r'data\fitzgerald\fitzgerald_gatsby.txt', 'r') as f:
fg_text = f.read()
gatsby_nlp = nlp(fg_text)
with open(r'data\hemingway\hemingway_sun_also.txt', 'r') as f:
sun_text = f.read()
sun_nlp = nlp(sun_text)
Now we can create a dictionary with all of our possible “standard” tags: tagDict = {w.pos: w.pos_ for w in gatsby_nlp}; we can also create one for all the “extended tags”: extendedTagDict = {w.pos: w.pos_ + "_" + w.tag_ for w in gatsby_nlp}. Next we create variables to hold all of the counts of each of the POS tags as follows:
gatsby_POS = pd.Series(gatsby_nlp.count_by(spacy.attrs.POS))/len(gatsby_nlp)
sun_POS = pd.Series(sun_nlp.count_by(spacy.attrs.POS))/len(sun_nlp)
Then we can get this into a dataframe and produce a nice plot:
df = pd.DataFrame([gatsby_POS, sun_POS], index=['fitzgerald', 'hemingway'])
df.columns = [tagDict[column] for column in df.columns]
df.T.plot(kind='bar')
plt.title('All the Different Kinds of (Standard) Parts of Speech', fontsize=16)
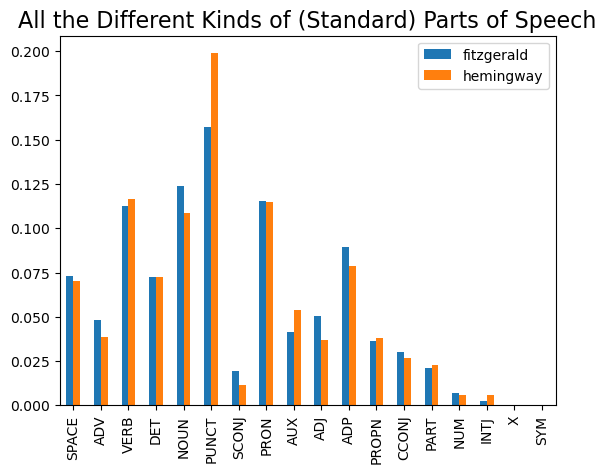
Then if we wanted to do similarly for the “extended” list of POS tags along with its corresponding plot:
df = pd.DataFrame([gatsby_POS, sun_POS], index=['fitzgerald', 'hemingway'])
df.columns = [extendedTagDict[column] for column in df.columns]
df.T.plot(kind='bar')
plt.title('All the Different Kinds of (Extended) Parts of Speech', fontsize=16)
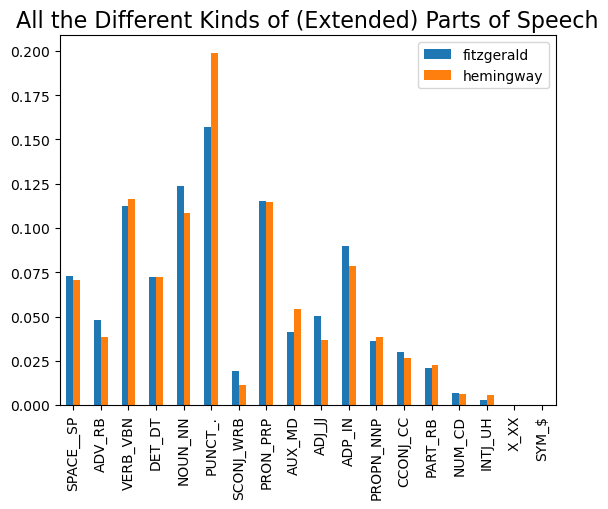
As Rice muses: “Is it true that Hemingway’s sentences are especially short?” and replies, “Hemingway’’’s sentences clock in about 7 words shorter than average, so yes: his sentences are short. Proust’s sentences, meanwhile, are really, really long. Surprisingly, the average sentence in The Grapes of Wrath is shorter than the average sentence in Hemingway’s writing.” This would seem to match our “extended” plot that showed Hemingway’s use of way more punctuation marks than in The Great Gatsby.
I also thought we might dig into the direct object counts for Hemingway, following the intuition (again, in Rice) that “Hemingway’s verbs (‘punched’, ‘stroked’, ‘galloped’, and so on) are visceral and active.” Here are some plots of those counts:
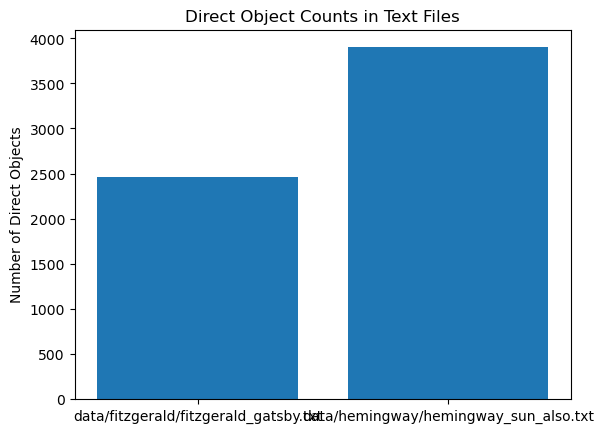
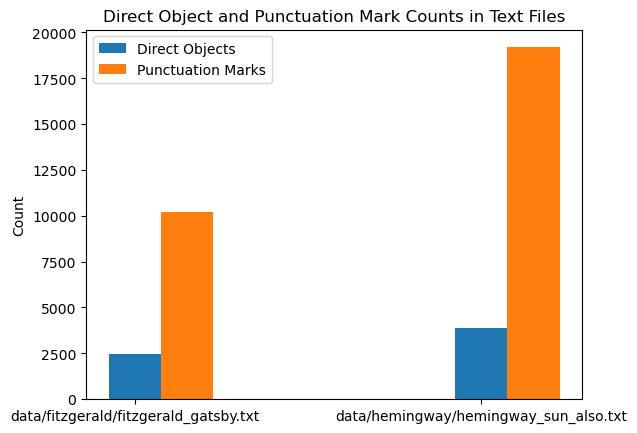
William, the student I mentioned in my previous post who got all the wheels turning re Hemingway, mentioned another little odd syntactic idiosyncrasy/tic of Hemingway that I would love to be able to pull out somehow. He said that he always noticed something that he called “the Hemingway and” where we would get sentences linked by an “and” where the phrases linked by the “and” are often hard to parse—often, he said, they will veer off on tangents that are hard to keep track of. Here is a nice example from “Cat in the Rain”:
“I want to pull my hair back tight and smooth and make a big knot at the back that I can feel,” she said. “I want to have a kitty to sit on my lap and purr when I stroke her.” “Yeah?” George said from the bed. “And I want to eat at a table with my own silver and I want candles. And I want it to be spring and I want to brush my hair out in front of a mirror and I want a kitty and I want some new clothes.” “Oh, shut up and get something to read,” George said. He was reading again.1
That second-to-last sentence might be a good example illustrating William’s intuition. The sentences are linked by “and,” but it’s not clear if there is some larger logic that is operating. Of course, in this case above, it seems simple enough to note the way in which the wife’s desire is the thing that coheres all of the different sentences together. It would be intriguing to see if we could quantify this intuition somehow. Does Hemingway’s work really have a plethora of sentences that look like this … and how might we program a script to find these kinds of things for us? Obviously, it wouldn’t be enough to just find all the sentences that had the “and” conjunction in it—and we we would want to find some way to somehow tag the two “domains” present in the clauses separated by “and” such that we could try to measure some kind of distance or proximity between the different regions or regimes of the clauses.
Sounds like a nice project—I’ll spend some think-time on this and see what I can come up with—more to come, as usual, to be sure.
This story is available in The Complete Short Stories of Ernest Hemingway: The Finca Vigía Edition (New York: Charles Scribner’s Sons, 1987), p. 131. ↩︎
naive bayes classifier random forest classifier decision tree algorithm machine learning seaborn scikit-learn matplotlib data visualization confusion matrix python spaCy jupyter jupyter notebooks Canvas LMS Canvas Instructure data visualization ernest hemingway literature fiction
1002 Words
2023-04-10 00:01