9 minutes
Interacting with the Canvas Live API
In a previous post (“Automating Canvas Discussion Board Grading and Feedback”), I recounted some of the ways I’ve been using the CanvasAPI python library from ucfopen to help with responding to discussion board posts from students each week. I have had a couple of times when running the script shown in that post where something goes slightly awry: perhaps I have mistyped one of the student or assignment ids and the script runs into an error while iterating through the dataframe that contains all of the data I want to upload. There’s no error handling in that script, so if I go and correct the mistake in the data file and then rerun the script, it now ends up reposting all of the data in the rows that it runs through before running into the line of code containing the snag. I opened up an “issue” on ucfopen’s github, asking where I would go via the canvasapi library to determine if a particular submission has any comments already uploaded to it—this would be one way to handle the potential duplication of comments. I got a really nice response from IonMich (Ioannis Michaloliakos) for how to handle this. For some reason that I’m not quite sure I can account for, this response pushed me to wonder if I couldn’t myself figure out how to just interact with the Canvas Live API itself, rather than going through the python wrapper provided via canvasapi. (I have used the requests library in python for other projects before, but I got to thinking if things might be easier to just utilize that library alone.) This launched me off to the official documentation for Instructure’s API.
Following the path laid out by IonMich’s response, I wandered over to the Submissions endpoint, zeroing in on the method that will allow one to “Grade or comment on multiple submissions.” Having found the method that would seem to do what I want to do, the next step was getting the data I wanted to upload in the correct form and structure. As detailed in the earlier, previously mentioned, post, I am still keeping the data to be uploaded to Canvas in a .json file that has been slightly altered:
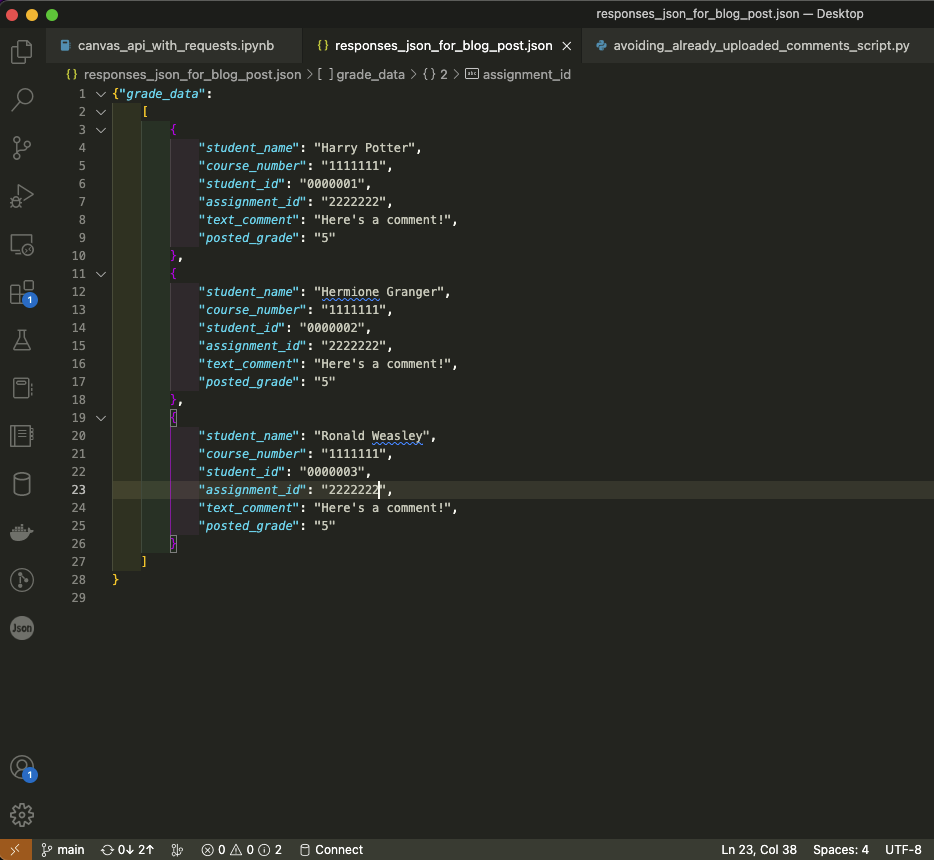
Typical workflow will follow: library import, getting all the information we need to successfully query the API, etc.:
import json
import requests
URL = # Here we'll store the URL to the appropriate API endpoint: one can play around with the Canvas Live API [here](https://canvas.instructure.com/doc/api/live)—although one will need to alter this to utilize the base URL to one's own Canvas system—through the web ahead of time to test out whether you've got the correct endpoint, that it's returning the data one expects, etc.)
API_KEY = XXXXX # Here's where you insert your own unique API key
course_number = XXXXXXX # This variable will the course_id number that has the assignments one wants to upload grades to/for
So what we need to do first is to get our data from the .json file into a format that we can then appropriately pass to the “Request Parameters” of the API (here again is the documentation about what these parameters should look like).
Given that I have data that looks like the screenshot above, we need to do a little tiny bit of reworking here—although certainly not much, all things considered.
with open('responses_json_for_blog_post.json') as f:
data = json.load(f)
As seasoned veterans know, the json.load returns us a Python dictionary—in our case it gives us a dictionary with a single key, "grade_data". The value for that key is itself a list of dictionaries:
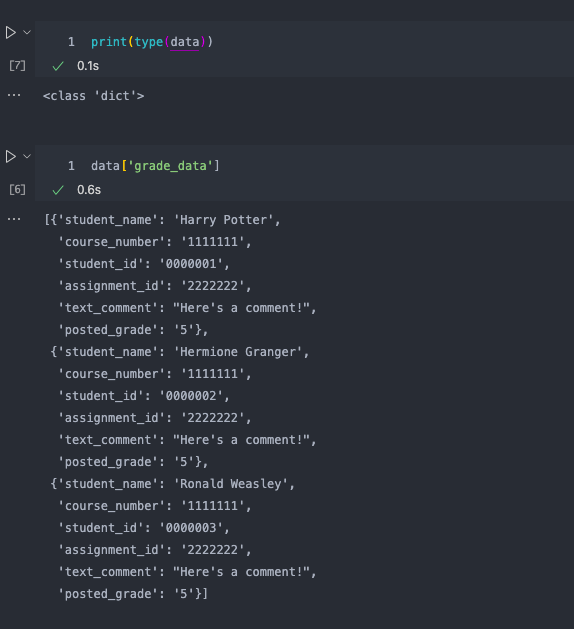
Now we just need to write a (very!) simple for loop that will let us extract out the necessary data to feed as parameters to the POST call:
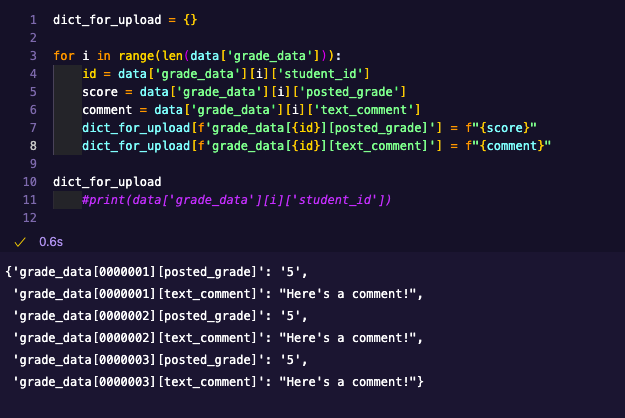
dict_for_upload = {}
for i in range(len(data['grade_data'])):
id = data['grade_data'][i]['student_id']
score = data['grade_data'][i]['posted_grade']
comment = data['grade_data'][i]['text_comment']
dict_for_upload[f'grade_data[{id}][posted_grade]'] = f"{score}"
dict_for_upload[f'grade_data[{id}][text_comment]'] = f"{comment}"
dict_for_upload
This results in something that looks like the following:
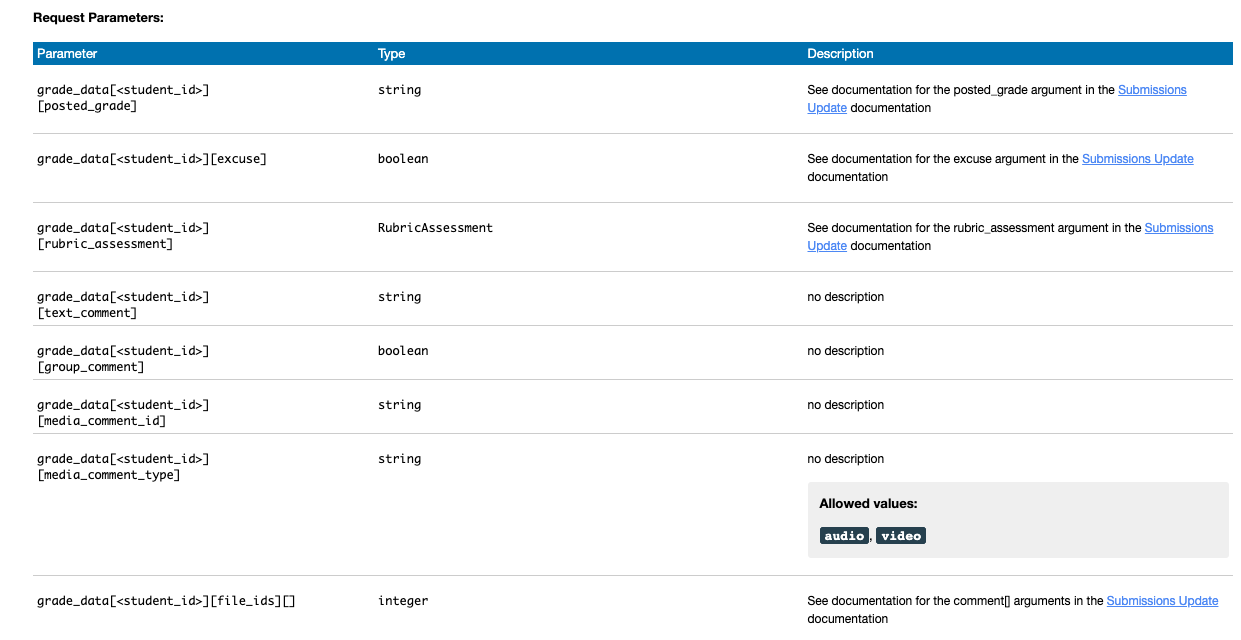
Of course, we’re shooting for something that looks like this:
Looks good! Now all we need to do is get everything set up properly for the requests library.
As with so much here in this whole “computer science” realm, one can often get exactly what they want in a single line of code:
header_argument = {"Authorization": "Bearer " + API_KEY}
response = requests.post(URL, headers=header_argument, data=dict_for_upload)
Simple as that.
Of course, the big question here is which avenue to prefer taking here: going through the ucf canvasapi wrapper or just dealing directly with the Instructure API. Furthermore, there is still the issue of how might want to do deal with the concern that started this investigation off in the first place—namely, making sure no duplicate comments get uploaded if the script fails somewhere along the line in the whole upload process. Of course, writing a function with the plan to use it directly with the API (not through the wrapper) seems easy enough. When you query the Instructure API to look at the data that contains whether or not a comment on a submission has been entered, one gets a response that has a key, submission_comments, containing a list with a dictionary that has a sub-key, comment. It’s easy to check the response, if it gives us an empty list, then there’s no existing comment, otherwise it returns the actual comment already posted, along with other data, of course. Again, once we know where that information is, one can simply write some code to check it before uploading the comments—thus avoiding the possibility of duplicating comments. Something not all that sophisticated would seem to do the trick (one would just need to make sure they were hitting the right data—submission_comment[0]['comment'] is the right spot to look and is what should be passed to the function below):
def check_if_comments_already_exist(submission_comments_field):
if submission_comments_field == []:
updated = False
else:
updated = True
print(updated)
Then we just incorporate that into the for loop so we get no duplicate comments added to each submission. We also need to make sure that we query the correct API endpoint/address to get the information about the assignment—once again, the official Instructure API docs help out here:

It strikes me as perhaps much easier to deal directly with the Instructure API rather than going through the wrapper. I suppose it’s difficult to give some principled reason for preferring one over the other. I suppose one could invoke something like “proximity” and “closeness” in terms of an idea like “mediation.” Best to reduce the number of mediations in between where one is and where one wants to get to … something more to ponder and ruminate upon, to be sure.
(All code and sample testing data for this post is available in the following repository.)
Addendum #1, Tuesday, 17 January 2023:
After spending a couple of days working on writing some functions to handle all of this—included a big one that contains all of the sub-functions necessary to read in a datafile and then upload everything to the proper place, I found myself noticing an odd and peculiar little illusion in my thinking. I know that so much in data analytics and science is data wrangling, getting data into some kind of structured format that you can then do something with, obviously. One could say that the data coming from the Instructure API is incredibly well-structured. I think that’s pretty much true. Thus, in working directly with the API, one doesn’t need to do a ton of data wrangling, although you do have to do some, especially in terms of getting the data structured so that the API gets the data it’s expected, i.e. like with the grade_data['text_comment'] and grade_data['posted_score'] dictionary keys, etc. But all in all, not much wrangling. Now, of course, when you use the ucfopen python wrapper, the data that’s being utilized by the wrapper is just as structured as when you don’t work through the wrapper. But for some reason, that feels not to be the case—and I really haven’t the foggiest idea why.
Well, that’s not totally true—I think I do have some idea of why … maybe a simple example will suffice. When you want to get a list of users in a Canvas course, you can do the following to get the information via the canvasapi (and here I’m just following the example from the official documentation here):
canvas = Canvas(API_URL, API_KEY)
course = canvas.get_course(course_number)
all_users = course.get_users()
for user in all_users:
print(user)
What gets printed out is bare bones. You get a readout that looks something like this:
student_01_first_name student_01_middle_name student_01_last_name (student_id)
student_02_first_name student_02_middle_name student_02_last_name (student_id)
student_03_first_name student_03_middle_name student_03_last_name (student_id)
Of course, when going directly to the API, there’s a richness of information, comparatively speaking, that the wrapper doesn’t provide … which I’m sure is by design, for sure. If one wants to dig deeper, then more function calls are in order. Maybe this all isn’t that sophisticated. If one can get to their destination while only moving through one hoop (rather, than, say, another path that requires two or three of four hoops), then it would seem pretty to simple that the shorter route is preferable. Don’t get me wrong, I love the canvasapi library—it started me on many of journeys here on this Digital Forays blog, but I’m seeing the usefulness of being able to take slightly more direct paths. It may not have anything at all to do—really—with the structured (or unstructured) nature of the data (as, in this case, the data is structured either way), bit perhaps more to do with how the data is being accessed … as I say, I’ll have to continue stewing on this a bit more.
Addendum #2, Wednesday, 25 January 2023:
Here’s a full script to handle the uploading of grades and comments utilizing data in two .json files where the data is housed …:
# Script to Upload Discussion Board Comments for Weekly Student Posts
import json
import requests
API_KEY = # your Instructure Canvas API key goes here
header_argument = {"Authorization": "Bearer " + API_KEY}
course_number_id = # Canvas course number here ...
section_d_assignment_number = #assignment number if the course is split up into sections
section_e_assignment_number = # same as above—you can add as many variables here as required by your own use case ...
def create_dictionary_for_upload(json_data_file):
dict_for_upload = {}
for i in range(len(json_data_file['grade_data'])):
id = json_data_file['grade_data'][i]['student_id']
score = json_data_file['grade_data'][i]['posted_grade']
comment = json_data_file['grade_data'][i]['text_comment']
dict_for_upload[f'grade_data[{id}][posted_grade]'] = f"{score}"
dict_for_upload[f'grade_data[{id}][text_comment]'] = f"{comment}"
return dict_for_upload
def load_json_datafile(file_path):
with open(file_path, 'r') as f:
section_datafile = json.load(f)
return section_datafile
# The following function will get rid of all dictionaries for students who haven't anything to grade ...
def remove_specific_keys_if_empty(my_dict):
my_dict = {key: value for key, value in my_dict.items() if key not in ('posted_grade','text_comment') or value != ''}
return my_dict
def post_the_data(data_dict_to_upload, course_number_id, section_assignment_number):
section_response = requests.post(
# API address goes here,
headers=header_argument, data=data_dict_to_upload)
def process_and_upload(filepath, course_id_number, section_assignment_number):
json_data = load_json_datafile(filepath)
initial_dict = create_dictionary_for_upload(json_data)
dict_for_upload = remove_specific_keys_if_empty(initial_dict)
post_the_data(dict_for_upload, course_id_number, section_assignment_number)
section_d_filepath = # filepath for the .json file with the data to upload
section_e_filepath = # same as above ...
process_and_upload(section_d_filepath, course_number_id, section_d_assignment_number)
process_and_upload(section_e_filepath, course_number_id, section_e_assignment_number)
There it is … all nice and clean and tidy—and in a very, very small number of lines of code …
json python json library python jupyter jupyter notebooks Canvas LMS Canvas Instructure grading
1868 Words
2023-01-13 00:06 (Last updated: 2022-01-25 09:24)