12 minutes
Comparing Stylistic Tendencies of Recent United States Supreme Court Justices (Gorsuch, Kavanaugh, and Barrett)
General Introduction
(All of the code for this post is available in this repo here.)
Continuing off of the last two posts (here and here), I thought we might continue seeing what we could do with our Supreme Court Opinions dataset(s)—I was also fascinated and inspired by a nice little article on Wikipedia about the “Ideological leanings of United States Supreme Court justices,” which has some really nice images. I thought one might do a little exploratory work with the opinions of some of the more recently appointed Justices: in particular I wanted to look at the work done so far by Justices Gorsuch, Kavanaugh, and Barrett; perhaps a little PCA work to see if we could work through any potential stylistic similarities between their opinions so far. Given that none of the opinions by these newer Justices are in either of our USSC datasets (either from the Karsdorp, et. al. work or from the dataset available on Kaggle), we’ll have to do some data wrangling/scraping. We’ll focus in on utilizing the data gathered through the really awesome Court Listener website. I thought I would try to take us through all the steps I went through in order to pull down these Justices’ opinions. There are, of course, some things I figured out along the way to make the whole process a little more streamlined, but I’ll go through the non-streamlined paths and will try to show the spots where we could simplify things a good deal. (The more streamlined versions are available in the Appendix below.)
Data Wrangling/Gathering/Web Scraping Process
So, for starters we went to Court Listener’s main page and searched by the “Supreme Court” field, looking for all the opinions authored by Justice Kavanaugh. Next we loaded up some libraries:
import requests
import pandas as pd
from bs4 import BeautifulSoup
import re
pd.set_option('display.max_rows', 500)
pd.set_option('display.max_columns', 500)
pd.set_option('display.width', 1000)
We get a couple of pages returned to us with links to all of the opinions—so, we had two URLs that we then used Python’s request library to pull info off of:
url_one = "https://www.courtlistener.com/?type=o&q=&type=o&order_by=score%20desc&judge=Kavanaugh&stat_Precedential=on&court=scotus"
url_two = "https://www.courtlistener.com/?type=o&type=o&order_by=score+desc&judge=Kavanaugh&stat_Precedential=on&court=scotus&page=2"
page_one = requests.get(url_one)
page_two = requests.get(url_two)
Each of these pages has all the links to the individual pages with the opinions. On the first dry run, I just manually copied over all the links on the pages returned from the search and put them in a list:
kavanaugh_pages = [
"https://www.courtlistener.com/opinion/4581379/henry-schein-inc-v-archer-white-sales-inc/?type=o&type=o&order_by=score+desc&judge=Kavanaugh&stat_Precedential=on&court=scotus&page=1",
"https://www.courtlistener.com/opinion/4595874/rimini-street-inc-v-oracle-usa-inc/?type=o&type=o&order_by=score+desc&judge=Kavanaugh&stat_Precedential=on&court=scotus&page=1",
"https://www.courtlistener.com/opinion/4601080/air-liquid-systems-corp-v-devries/?type=o&type=o&order_by=score+desc&judge=Kavanaugh&stat_Precedential=on&court=scotus&page=1",
"https://www.courtlistener.com/opinion/4729776/mckinney-v-arizona/?type=o&type=o&order_by=score+desc&judge=Kavanaugh&stat_Precedential=on&court=scotus&page=1",
"https://www.courtlistener.com/opinion/4748672/barton-v-barr/?type=o&type=o&order_by=score+desc&judge=Kavanaugh&stat_Precedential=on&court=scotus&page=1",
"https://www.courtlistener.com/opinion/4757655/nasrallah-v-barr/?type=o&type=o&order_by=score+desc&judge=Kavanaugh&stat_Precedential=on&court=scotus&page=1",
"https://www.courtlistener.com/opinion/4757654/thole-v-u-s-bank-n-a/?type=o&type=o&order_by=score+desc&judge=Kavanaugh&stat_Precedential=on&court=scotus&page=1",
"https://www.courtlistener.com/opinion/4765904/barr-v-american-assn-of-political-consultants-inc/?type=o&type=o&order_by=score+desc&judge=Kavanaugh&stat_Precedential=on&court=scotus&page=1",
"https://www.courtlistener.com/opinion/4764453/agency-for-intl-development-v-alliance-for-open-society/?type=o&type=o&order_by=score+desc&judge=Kavanaugh&stat_Precedential=on&court=scotus&page=1",
"https://www.courtlistener.com/opinion/4838845/texas-v-new-mexico/?type=o&type=o&order_by=score+desc&judge=Kavanaugh&stat_Precedential=on&court=scotus&page=1",
"https://www.courtlistener.com/opinion/4869841/fcc-v-prometheus-radio-project/?type=o&type=o&order_by=score+desc&judge=Kavanaugh&stat_Precedential=on&court=scotus&page=1",
"https://www.courtlistener.com/opinion/4876196/jones-v-mississippi/?type=o&type=o&order_by=score+desc&judge=Kavanaugh&stat_Precedential=on&court=scotus&page=1",
"https://www.courtlistener.com/opinion/4885592/edwards-v-vannoy/?type=o&type=o&order_by=score+desc&judge=Kavanaugh&stat_Precedential=on&court=scotus&page=1",
"https://www.courtlistener.com/opinion/4891453/greer-v-united-states/?type=o&type=o&order_by=score+desc&judge=Kavanaugh&stat_Precedential=on&court=scotus&page=1",
"https://www.courtlistener.com/opinion/4894912/transunion-llc-v-ramirez/?type=o&type=o&order_by=score+desc&judge=Kavanaugh&stat_Precedential=on&court=scotus&page=1",
"https://www.courtlistener.com/opinion/4618958/apple-inc-v-pepper/?type=o&type=o&order_by=score+desc&judge=Kavanaugh&stat_Precedential=on&court=scotus&page=2",
"https://www.courtlistener.com/opinion/6457347/thompson-v-clark/?type=o&type=o&order_by=score+desc&judge=Kavanaugh&stat_Precedential=on&court=scotus&page=2",
"https://www.courtlistener.com/opinion/4627817/quarles-v-united-states/?type=o&type=o&order_by=score+desc&judge=Kavanaugh&stat_Precedential=on&court=scotus&page=2",
"https://www.courtlistener.com/opinion/6463787/united-states-v-vaello-madero/?type=o&type=o&order_by=score+desc&judge=Kavanaugh&stat_Precedential=on&court=scotus&page=2",
"https://www.courtlistener.com/opinion/4630087/manhattan-community-access-corp-v-halleck/?type=o&type=o&order_by=score+desc&judge=Kavanaugh&stat_Precedential=on&court=scotus&page=2",
"https://www.courtlistener.com/opinion/6479297/marietta-memorial-hospital-employee-health-benefit-plan-v-davita-inc/?type=o&type=o&order_by=score+desc&judge=Kavanaugh&stat_Precedential=on&court=scotus&page=2",
"https://www.courtlistener.com/opinion/6477908/american-hospital-assn-v-becerra/?type=o&type=o&order_by=score+desc&judge=Kavanaugh&stat_Precedential=on&court=scotus&page=2",
"https://www.courtlistener.com/opinion/4631844/flowers-v-mississippi/?type=o&type=o&order_by=score+desc&judge=Kavanaugh&stat_Precedential=on&court=scotus&page=2",
"https://www.courtlistener.com/opinion/6619823/oklahoma-v-castro-huerta/?type=o&type=o&order_by=score+desc&judge=Kavanaugh&stat_Precedential=on&court=scotus&page=2"
]
Now, obviously, BeautifulSoup (BS4) has functions that will automate this for us, but on this first run I went down the old-fashioned copy-and-paste route. So how do we scrape the information that we want from the pages that have the opinions? We should try some things out just on a single case before we go trying to grab all of the opinions we want, so here we avail ourselves of the BS4 parser:
test_grab = requests.get("https://www.courtlistener.com/opinion/4581379/henry-schein-inc-v-archer-white-sales-inc/?type=o&type=o&order_by=score+desc&judge=Kavanaugh&stat_Precedential=on&court=scotus&page=1")
soup = BeautifulSoup(test_grab.content, 'html.parser')
There is some specific information that we want to scrape off the web page—it would be nice to have things like the “Docket Number” of the case, perhaps the year the opinion was registered, the name of the case, what kind of opinion it was (Slip, etc.), and so on. Thus, we need to inspect the html to see where all this information resides. We can see, as an example, that the “Docket Number” is in the following block of HTML (so that let’s us know exactly what we want our script to look for):
<p class="bottom">
<span class="meta-data-header">Docket Number:</span>
<span class="meta-data-value">21-429></span>
</p>
So, what we want to do is write some code for BS4 to look for the above and pull the information from there. BS4 gives us all this nice functionality to, in our test case here, locate all of the information within a specific HTML tag using the find_all function. So let’s grab all the spans that we’re looking for here:
spans = soup.find_all('span', {'class': 'meta-data-value'})
print(spans[3].get_text())
Theget_text function will return us just the text within each of the span tags. The titles of the cases are contained within a different tag (and there’s only one of them on the page, so we can use the find() method instead of find_all): case_title = soup.find("meta", {'property': "og:title"})
Furthermore, the type of opinion can be found thusly:
opinion_type_soup = soup.find('pre', {'class': 'inline'}).get_text()
match = opinion_type_soup[opinion_type_soup.find('(')+1:opinion_type_soup.find(')')]
The type of opinion is also put within a set of parentheses, so we can just use a simple regex (following the method given here) to extract only the text within the parentheses, as we don’t really need it the open and closing parenthesis.
Now we should be able to put all of this into a for loop so that we can grab everything that we want and then feed it into a dataframe. First we initialize empty lists to store all of the data, run the loop to grab all the info we want and then append it all to the individual lists—once that’s all done we’ll create a dataframe from all of the lists.
kavanaugh_opinions = []
kavanaugh_case_years = []
kavanaugh_docket_numbers = []
kavanaugh_case_names = []
kavanaugh_opinion_types = []
kavanaugh_author_name_list = ['kavanaugh' for i in range(len(kavanaugh_pages))]
for page in kavanaugh_pages:
html_page = requests.get(page)
soup = BeautifulSoup(html_page.content, "html.parser")
spans = soup.find_all('span', {'class': 'meta-data-value'})
opinion = soup.find(class_='plaintext').get_text()
kavanaugh_opinions.append(opinion)
kavanaugh_case_years.append(spans[0].get_text())
case_title = soup.find("meta", {'property': "og:title"})
kavanaugh_case_names.append(case_title['content'])
kavanaugh_docket_numbers.append(spans[3].get_text())
opinion_type_soup = soup.find('pre', {'class': 'inline'}).get_text()
match = opinion_type_soup[opinion_type_soup.find('(')+1:opinion_type_soup.find(')')]
kavanaugh_opinion_types.append(match)
kavanaugh_opinion_dataframe = pd.DataFrame(
{'authors': kavanaugh_author_name_list,
'case_id': kavanaugh_docket_numbers,
'text': kavanaugh_opinions,
'type': kavanaugh_opinion_types,
'year': kavanaugh_case_years}
)
After this we now have a nice little dataframe that contains all of the information we wanted to scrape:
| authors | case_id | text | type | year | |
|---|---|---|---|---|---|
| 0 | kavanaugh | \n 17-1272\n ... | (Slip Opinion) OCTOBER TERM, 2018... | Slip Opinion | \n January 8th, 2019\n ... |
| 1 | kavanaugh | \n 17-1625\n ... | (Slip Opinion) OCTOBER TERM, 2018... | Slip Opinion | \n March 4th, 2019\n ... |
| 2 | kavanaugh | \n 17-1104\n ... | (Slip Opinion) OCTOBER TERM, 2018... | Slip Opinion | \n March 19th, 2019\n ... |
| 3 | kavanaugh | \n 18-1109\n ... | (Slip Opinion) OCTOBER TERM, 2019... | Slip Opinion | \n February 25th, 2020\n ... |
| 4 | kavanaugh | \n 18-725\n ... | (Slip Opinion) OCTOBER TERM, 2019... | Slip Opinion | \n April 23rd, 2020\n ... |
Now that we have everything working here for Kavanaugh’s opinions, it’s simple enough to just rinse and repeat with all the opinions by Gorsuch and Barrett. We thus end up with three different dataframes that we can concatenate together into a single one. We’ll also output the dataframe to a .jsonl file for further analysis and so that we don’t constantly query the Court Listener website each time:
kavanaugh_gorsuch_barrett_combined = pd.concat([kavanaugh_opinion_dataframe, gorsuch_opinion_dataframe, barrett_opinion_dataframe], ignore_index=True)
kavanaugh_gorsuch_barrett_combined.to_json('kavanaugh_gorsuch_barrett_combined.jsonl', orient='records', lines=True)
Exploratory Data Analysis (EDA)
Now that we’ve got everything wrangled together into a single dataframe, what might we want to do with this now that it’s in a form that’s ready for analysis? As noted in the introductory section above, what if we do a little bit of visualization of the three Justices’s writing styles? Actually, before we move into running through this some algorithms, let’s do a teensy-tiny bit of cleaning of data in the dataframe, as we definitely have some things we won’t want to utilize (new lines [\n], for example, in the text column). Thus, let’s do a little text cleanup (following Susan Li’s nice little gist and function here)
def clean_text(text):
"""
text: a strin to clean-up
return: modified initial string cleaned-up
"""
text = BeautifulSoup(text, "lxml").text # HTML decoding
text = text.lower() # lowercase text
text = REPLACE_BY_SPACE_RE.sub(' ', text) # replace REPLACE_BY_SPACE_RE symbols by space in text
text = BAD_SYMBOLS_RE.sub('', text) # delete symbols which are in BAD_SYMBOLS_RE from text
text = ' '.join(word for word in text.split() if word not in STOPWORDS) # delete stopwors from text
return text
So let’s have a look at some visualizations—maybe how many many words are in each of the different opinions? This time around I felt like using Plotly library largely because I wanted to learn and play around with it a little bit more (I feel pretty confident with [Matplotlib] (https://matplotlib.org/stable/users/index.html) and figure it might be nice to try a new graphing library). We can very easily get the word counts for the text column as follows: df['num_words'] = df.text.apply(lambda x: len(x.split())). Then it’s a simple call to plot the histogram: fig = px.histogram(df, x='num_words', color='authors', title='Number of Words per Case by Justices Gorsuch, Kavanaugh, and Barrett'):
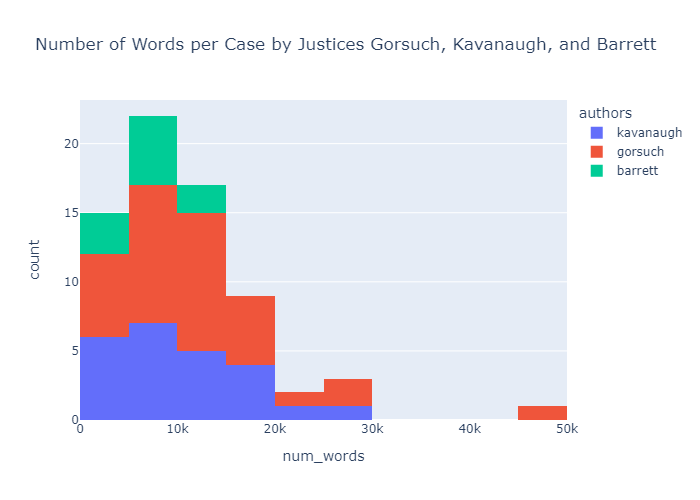
Principal Component Analysis (PCA)
So let’s continue down the PCA route and see what we can see. As usual, we need to vectorize the texts and we, again, as per usual, will use that handy ol’ sklearn library. After the imports we’ll create and initialize a PCA object, fit and transform the df['text'] column, and then set up a DecisionTreeClassifier() (for more information on the use of PCA before utilizing the decision tree function, hop over here):
pca = PCA(n_components=3)
vectorized_documents = vectorizer.fit_transform(df['text'])
vectorized_documents = vectorized_documents.todense()
Xd_full = pca.fit_transform(vectorized_documents)
clf = DecisionTreeClassifier(random_state=14)
y_full = df['authors']
scores_reduced = cross_val_score(clf, Xd_full, y_full, scoring='accuracy')
We can then plot our vectors thusly (following code provided by Robert Layton in his really fantastic book, Learning Data Mining with Python, pp. 97-98):
classes = set(y_full)
print(classes)
colors = ['red', 'blue', 'green']
for cur_class, color in zip(classes, colors):
mask = (y_full == cur_class).values
plt.scatter(
Xd_full[mask, 0],
Xd_full[mask, 1],
marker='o',
color=color,
label=cur_class,
alpha = 0.3)
plt.legend()
plt.title("PCA Analysis of Opinions by Justices Gorsuch, Kavanaugh, and Barrett")
plt.show()
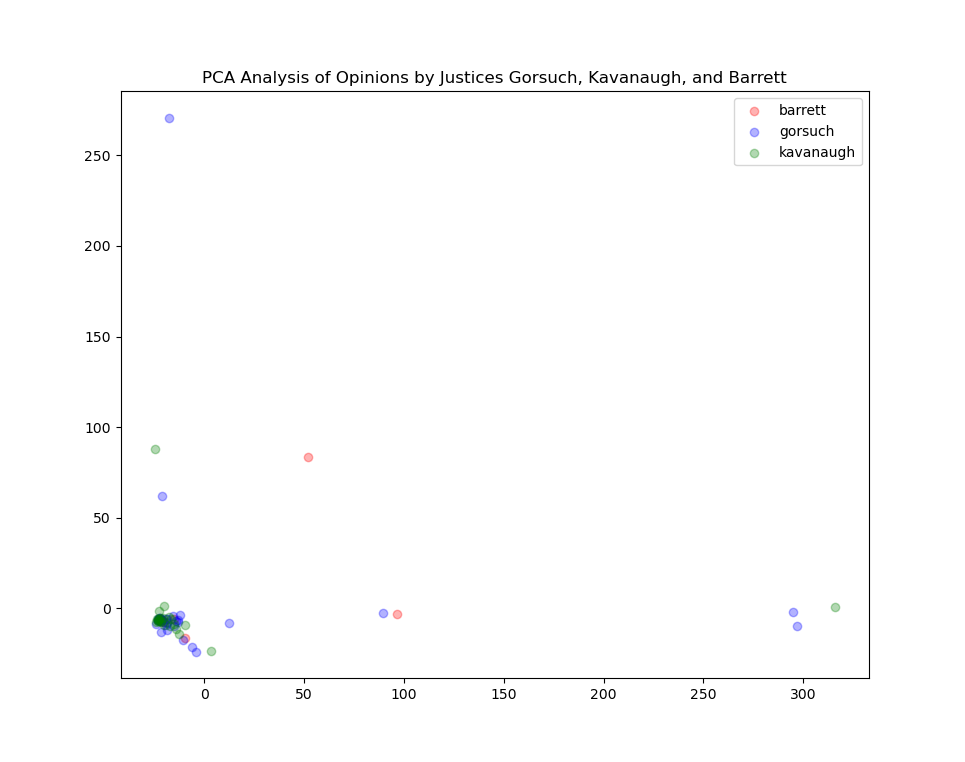
So we see the algorithm finding a good deal of similarity between opinions by these three justices. We could also wonder a little bit what things would look like if we added some Justices on the opposite side of the ideological spectrum. What if we added opinions by Sotomayor and Kagan to the plot?
That would give us a plot that looks like this:
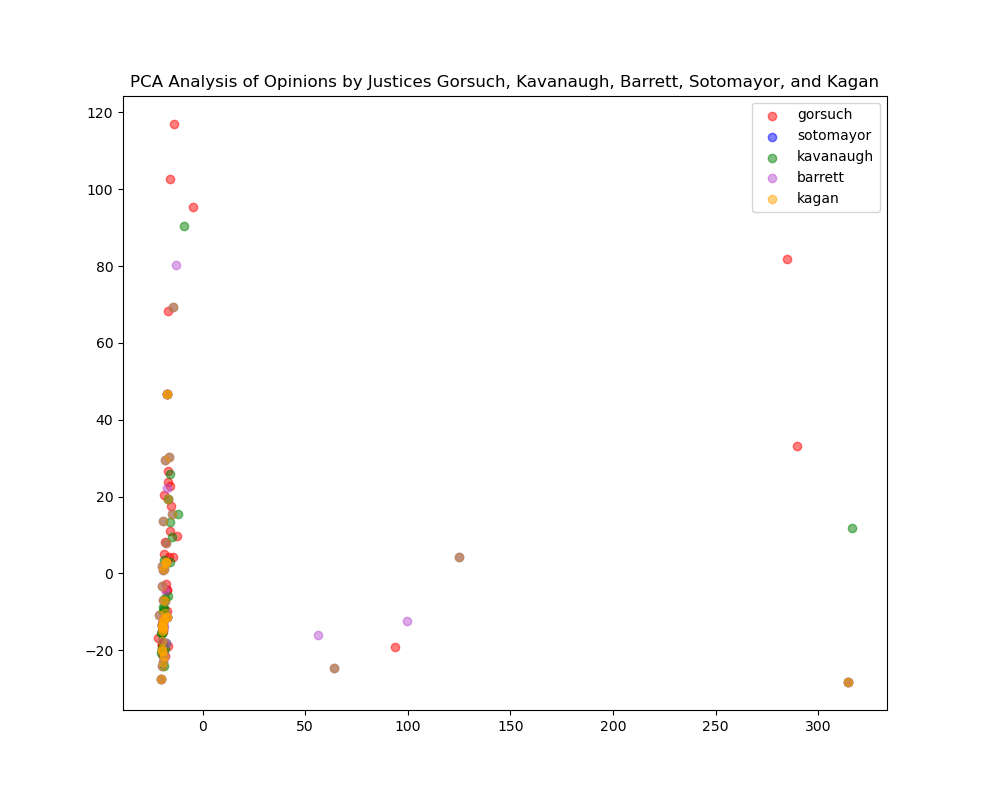
Oh—and we can easily get the word counts, of course:
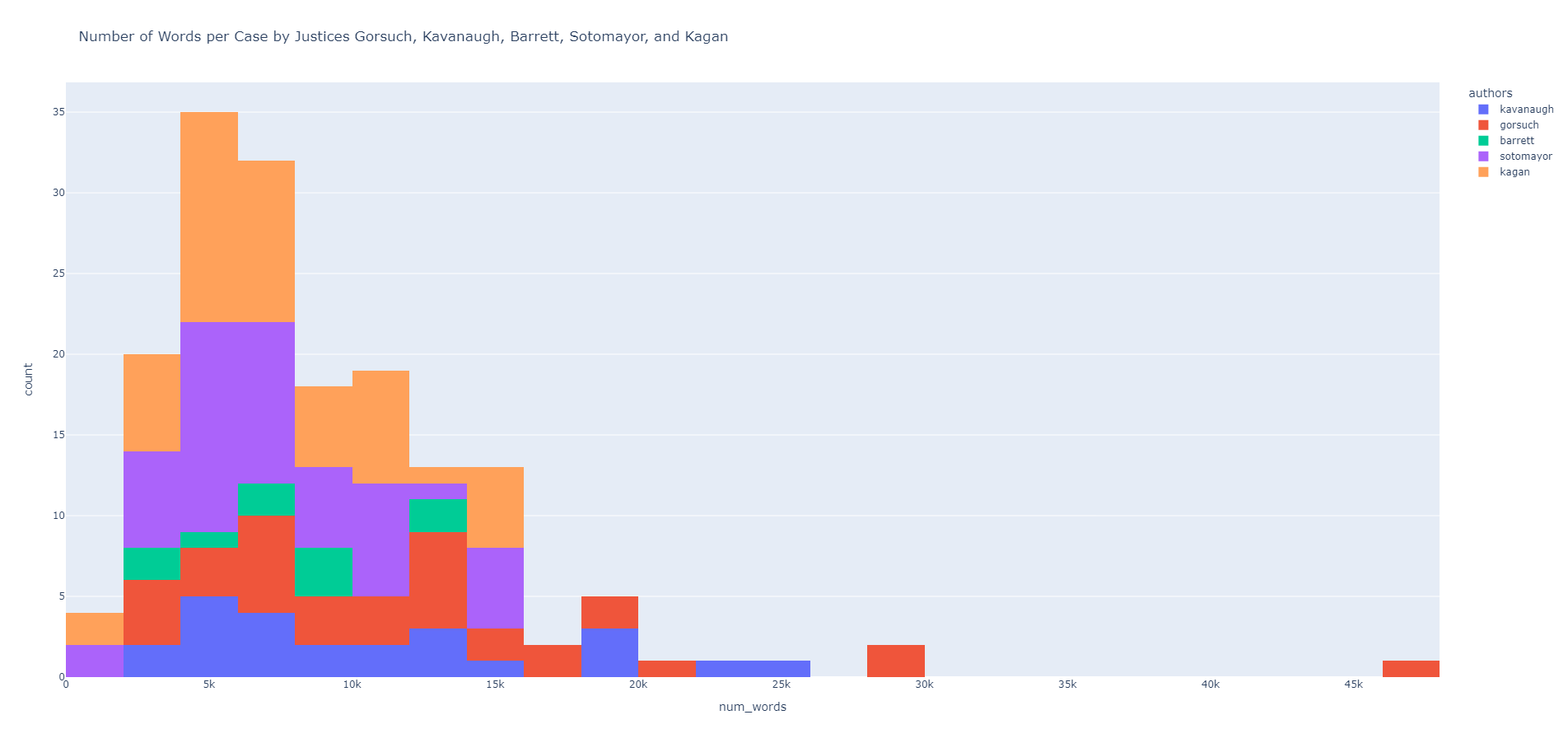
We could—also—do a similar analysis with the very large Kaggle dataset as well. That too is simple enough with all the functions we’ve got so far (stand-alone notebook with all the code is available directly from here).
The main parameter that we passed to the PCA() function of scikitlearn called n_components is one we could tweak a little bit. We could also utilize the explained_variance_score metric as well to see exactly how much variance is explained by the number of components utilized (for more info on this head this way):
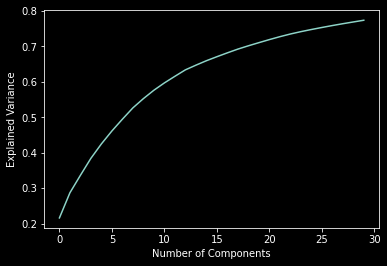
We can then plot all of the opinions in the entire dataset with just a few lines of code:
pca = PCA(n_components=30)
vectorized_documents = vectorizer.fit_transform(df['text'])
vectorized_documents = vectorized_documents.todense()
Xd_full = pca.fit_transform(vectorized_documents)
clf = DecisionTreeClassifier(random_state=14)
y_full = df['author_name']
scores_reduced = cross_val_score(clf, Xd_full, y_full, scoring='accuracy')
plt.figure(figsize=(20, 10))
colors = ['red', 'green', 'blue', 'mediumorchid', 'orange']
classes = set(y_full)
for cur_class, color in zip(classes, colors):
mask = (y_full == cur_class).values
plt.scatter(Xd_full[mask, 0], Xd_full[mask, 1], marker='s', cmap='viridis', label=cur_class, alpha = 0.5)
#plt.legend()
plt.title("PCA Analysis of All Opinions in the Kaggle SCOTUS Dataset")
plt.show()
that results in the plot here:
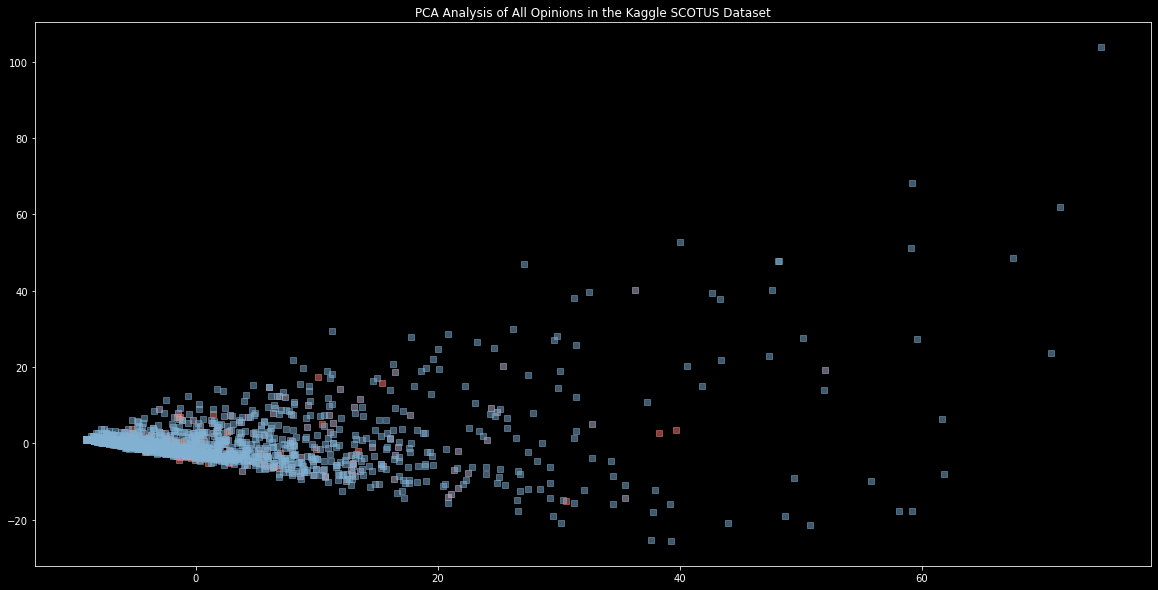
My guess is that this clustering is due to the very domain-specific area that we’re working with here: namely, the legal system. It makes sense that most of the opinions would be found to be quite similar to one given the shared genre. It would be curious to see what the plots looked like when we tried texts from quite different genres. Sounds like an idea for another project!
Appendix
We can definitely do a little bit of pruning with the scraping functions—and I thought I could lay out the logic of that here in the Appendix. For one thing, rather than copy and pasting all of the links on each results’ page from Court Listener, one should write some code that will head to each of the returned results pages, pull down all the links on each page, and then move on from there. In other words, we could put the results’ pages (there were three in total) for all of Justices Sotomayor’s and Kagan’s opinions into lists:
sotoymayor_pages = [
"https://www.courtlistener.com/?type=o&q=&type=o&order_by=score%20desc&judge=sotomayor&stat_Precedential=on&court=scotus",
"https://www.courtlistener.com/?type=o&type=o&order_by=score+desc&judge=sotomayor&stat_Precedential=on&court=scotus&page=2",
"https://www.courtlistener.com/?type=o&type=o&order_by=score+desc&judge=sotomayor&stat_Precedential=on&court=scotus&page=3"
]
kagan_pages = [
'https://www.courtlistener.com/?type=o&q=&type=o&order_by=score%20desc&judge=kagan&stat_Precedential=on&court=scotus',
'https://www.courtlistener.com/?type=o&type=o&order_by=score+desc&judge=kagan&stat_Precedential=on&court=scotus&page=2',
'https://www.courtlistener.com/?type=o&type=o&order_by=score+desc&judge=kagan&stat_Precedential=on&court=scotus&page=3'
]
Then we want to alter the scraping script a little bit to grab all of the links (all the <a href> tags) on the page—in this case (again, after looking at the HTML), we want to find the following:
<a href="/opinion/1742/wood-v-allen/?type=o&q=&type=o&order_by=score%20desc&judge=sotomayor&stat_Precedential=on&court=scotus"
class="visitable">
Wood v. Allen
(2010)
</a>
Again, we grab all the links with BS4 and then append them to a list:
spans = soup.findAll('a', {'class': 'visitable'}, href=True)
links = []
for span in spans:
link = span['href']
links.append(link)
full_links = ["https://www.courtlistener.com" + link for link in links]
print(full_links)
This will give us a list with the full URLs to each of the different pages containing their opinions. From there, we can feed that into the other scraping functions and grab all of the metadata (“Case Name,” “Docket Number,” year, opinion type, etc.) from way up above, feed it, again, all into a single dataframe for further analysis. We can even go a step further and wrap all this work in some functions. The scraping functions utilized here look like the following (cleaned-up a bit and including a simple print statement to let us know which pages do not contain the text of the opinion in the plaintext tag):
def get_all_links(list_of_pages):
links = []
for page in sotoymayor_pages:
html_page = requests.get(page, headers=header_argument)
soup = BeautifulSoup(html_page.content, "html.parser")
spans = soup.findAll('a', {'class': 'visitable'}, href=True)
for span in spans:
link = span['href']
links.append(link)
full_links = ["https://www.courtlistener.com" + link for link in links]
return(full_links)
def scrape_all_data_and_generate_dataframe(list_of_links, author_name):
author_opinions = []
author_case_years = []
author_docket_numbers = []
author_case_names = []
author_opinion_types = []
author_name_list = [author_name for i in range(len(list_of_links))]
for page in list_of_links:
html_page = requests.get(page, headers=header_argument)
soup = BeautifulSoup(html_page.content, "html.parser")
spans = soup.find_all('span', {'class': 'meta-data-value'})
if soup.find(class_='plaintext') is None:
opinion = "This case didn't have any plain text available on the web page ..."
author_opinions.append(opinion)
else:
opinion = soup.find(class_='plaintext').get_text()
author_opinions.append(opinion)
author_case_years.append(spans[0].get_text())
case_title = soup.find("meta", {'property': "og:title"})
author_case_names.append(case_title['content'])
author_docket_numbers.append(spans[3].get_text())
if soup.find('pre', {'class': 'inline'}) is None:
author_opinion_types.append("No opinion type submitted.")
else:
opinion_type_soup = soup.find('pre', {'class': 'inline'}).get_text()
match = opinion_type_soup[opinion_type_soup.find('(')+1:opinion_type_soup.find(')')]
author_opinion_types.append(match)
print(f"Successfully parsed {page}")
author_opinion_dataframe = pd.DataFrame(
{'authors': author_name_list,
'case_id': author_docket_numbers,
'text': author_opinions,
'type': author_opinion_types,
'year': author_case_years}
)
return(author_opinion_dataframe)
digital humanities machine learning supervised machine learning matplotlib data visualization work stuff python python for digital humanities pandas PCA principal component analysis united states supreme court opinions sklearn ussc
2370 Words
2022-07-11 00:01