2 minutes
Linear Regression in the Humanities(?!?!) … not quite
Working my way through some of the new lessons from Codecademy’s new “Data Scientist: Natural Language Processing Specialist” path, I was returning to some of the lessons on linear regression usage in machine learning contexts. I also happened across a really fantastic post from the “LaTeX Ninja” on “Machine Learning for the Humanities: A Very Short Introduction”—I hadn’t yet come across this site yet and find it full of all kinds of fantastic little nuggets. I myself have been thinking quite a bit about what’s in the just mentioned post, especially with regards to “finding datasets” for machine learning that would be nicer test cases for those of us working with machine learning within the context(s) of the humanities. No doubt one can learn a ton about the whole linear regression method when charting stock prices of sales at a restaurant or other scenarios where linear regression would be a helpful methodology of study and analysis. The [UCI Machine Learning Repository] has fantastic things up on it, but, as the Ninja notes, datasets tailored towards the humanities are perhaps pretty sparse (there is a “Victorian Era Authorship Attribution Data Set”) that is promising, but, as I say, good datasets are perhaps few and far between.
In the meantime, I have been working my way through Émile Zola’s 1885 novel, Germinal. I thought it might be interesting to see if I could find some data on French coal production. That led me down a rather nice rabbit hole of sorts where I learned about how difficult it is to get energy data from the IEA (International Energy Agency). I was able to find some data on the St. Louis FRED site. There were a couple of datasets available here and here].
A gist for the following three plots is available here along with the dataset in .csv format.
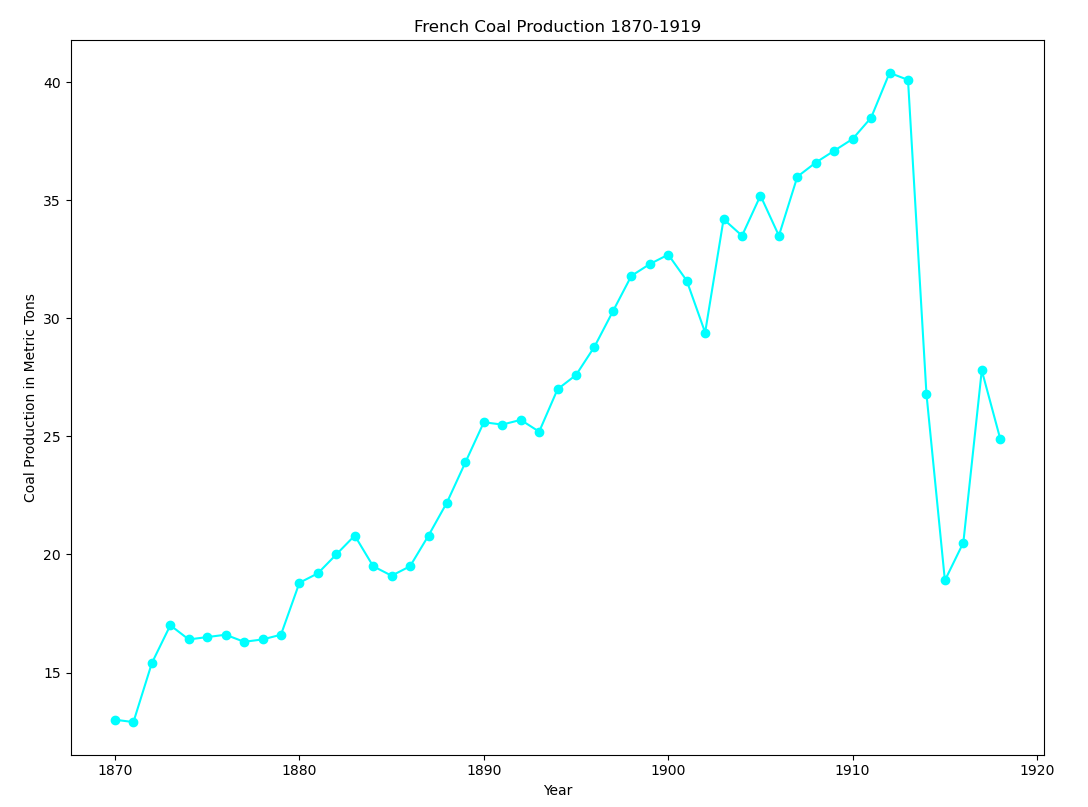
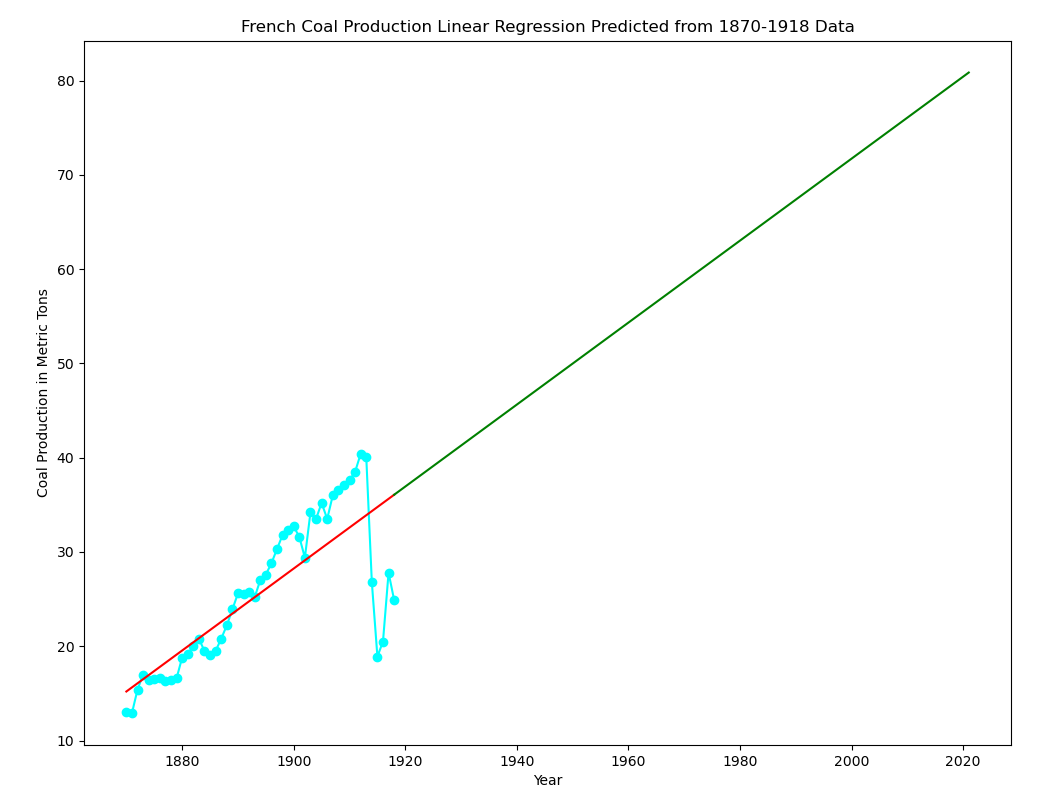
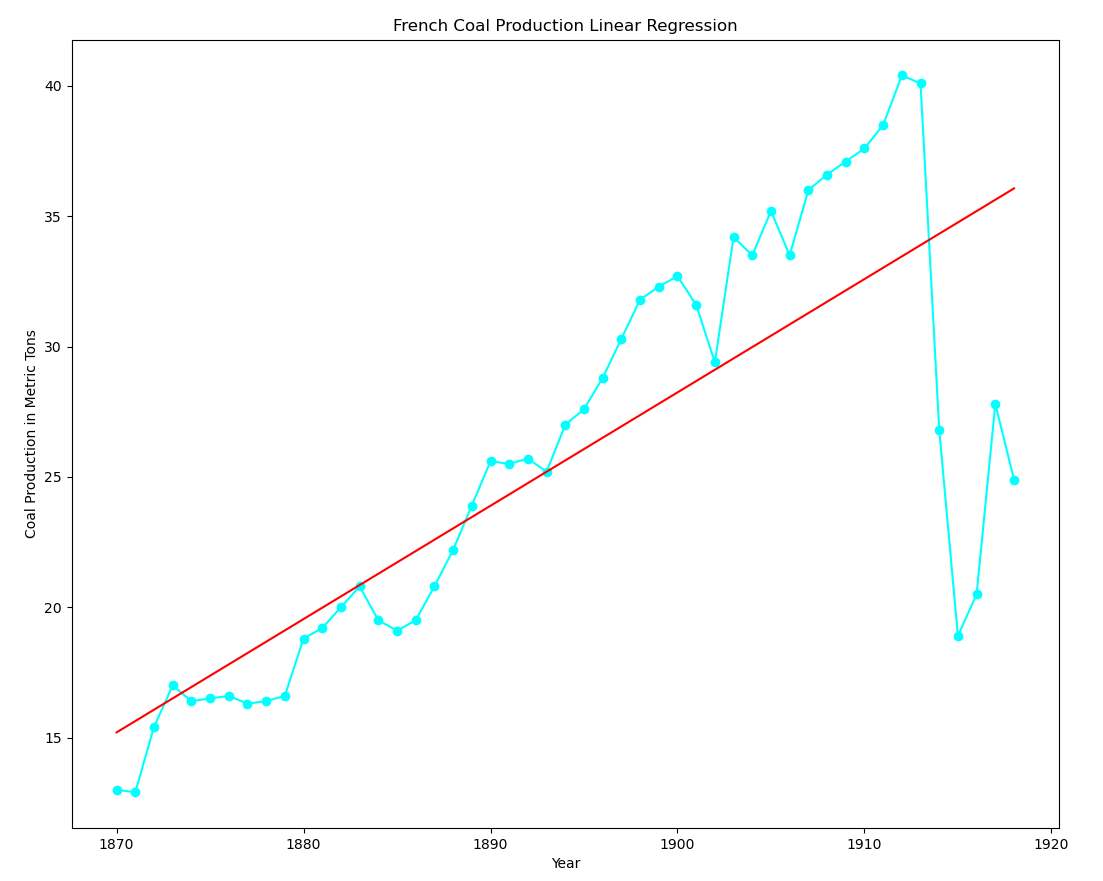
Using the second dataset with information from 1918 to 1938 (repo here):
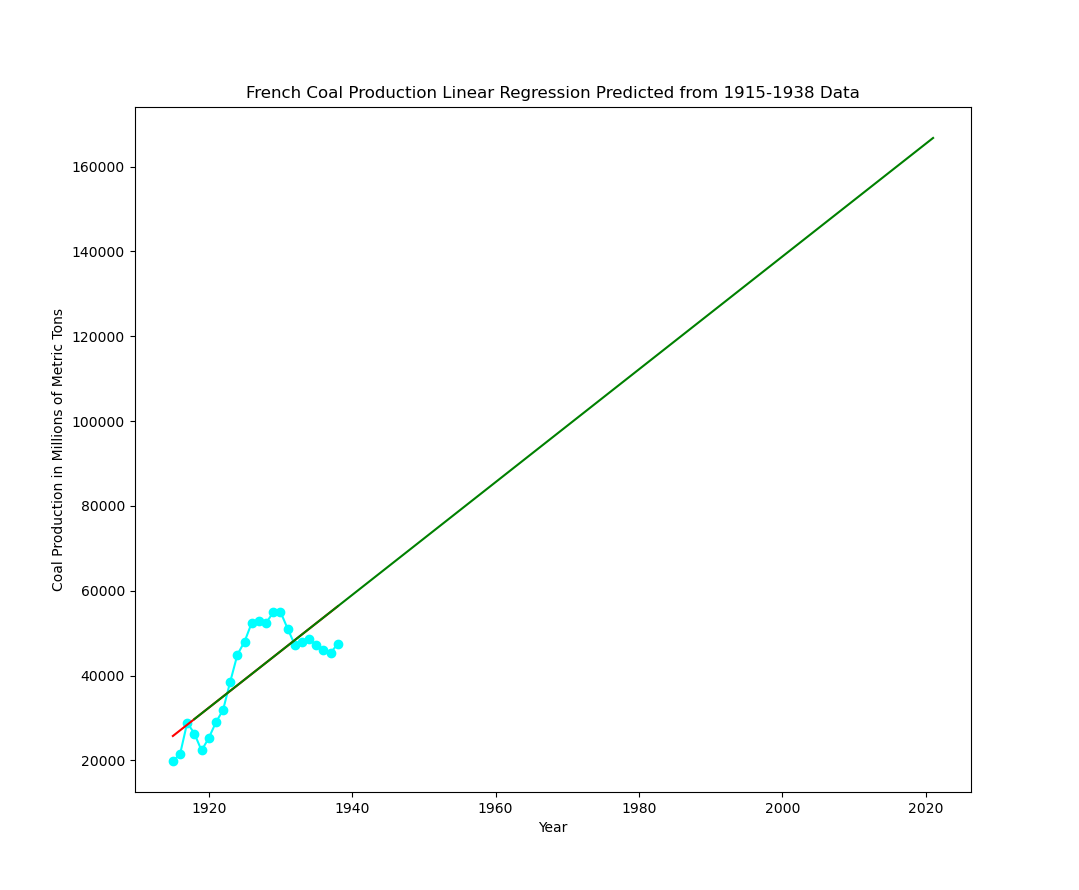
As the LaTeX Ninja noted, it would be nice to have some very humanities-specific datasets to work with here.
digital humanities machine learning supervised machine learning linear regression french coal production historical datasets matplotlib data visualization work stuff python python for digital humanities pandas codecademy data scientist-natural language processing specialist NLP
338 Words
2022-06-01 00:01