3 minutes
Fetching Data from a TOML File into a HUGO Table
Continuing to learn the whole HUGO ecosystem here, I figured I would try a little testing of some things. What if I had a bunch of data in a simple .json or .toml or .yaml or whatever file and wanted to pull/fetch data from that file into one of my posts? I did have some data from the last post about Henry James’s use of certain words that we used to generate some of the graphs. A little bit of fiddling around on the HUGO Discourse site, which provides a mountain of posts yielded some rather simple little shortcodes to fetch and pull data from another file stored in the data folder of this HUGO website. (Two other short writeups were quite helpful as well: here and here and also here and in this short YouTube video from “Pragmatic Reviews”.)
Assuming we had a .toml file that looked like the following,
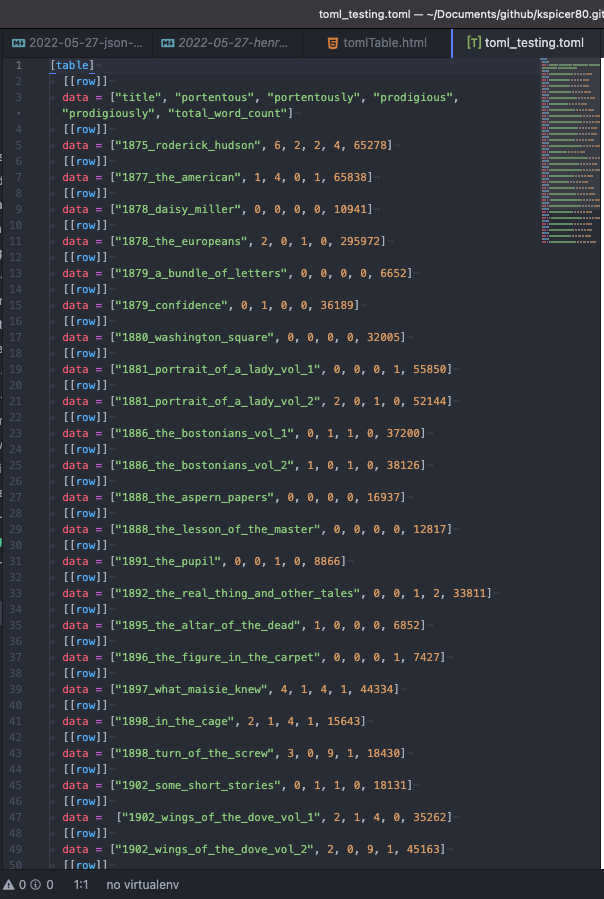 ,
,
it’s pretty simple to get that data fetched and into a table here in this post, like this:
| title | portentous | portentously | prodigious | prodigiously | total_word_count |
|---|---|---|---|---|---|
| 1875_roderick_hudson | 6 | 2 | 2 | 4 | 65278 |
| 1877_the_american | 1 | 4 | 0 | 1 | 65838 |
| 1878_daisy_miller | 0 | 0 | 0 | 0 | 10941 |
| 1878_the_europeans | 2 | 0 | 1 | 0 | 295972 |
| 1879_a_bundle_of_letters | 0 | 0 | 0 | 0 | 6652 |
| 1879_confidence | 0 | 1 | 0 | 0 | 36189 |
| 1880_washington_square | 0 | 0 | 0 | 0 | 32005 |
| 1881_portrait_of_a_lady_vol_1 | 0 | 0 | 0 | 1 | 55850 |
| 1881_portrait_of_a_lady_vol_2 | 2 | 0 | 1 | 0 | 52144 |
| 1886_the_bostonians_vol_1 | 0 | 1 | 1 | 0 | 37200 |
| 1886_the_bostonians_vol_2 | 1 | 0 | 1 | 0 | 38126 |
| 1888_the_aspern_papers | 0 | 0 | 0 | 0 | 16937 |
| 1888_the_lesson_of_the_master | 0 | 0 | 0 | 0 | 12817 |
| 1891_the_pupil | 0 | 0 | 1 | 0 | 8866 |
| 1892_the_real_thing_and_other_tales | 0 | 0 | 1 | 2 | 33811 |
| 1895_the_altar_of_the_dead | 1 | 0 | 0 | 0 | 6852 |
| 1896_the_figure_in_the_carpet | 0 | 0 | 0 | 1 | 7427 |
| 1897_what_maisie_knew | 4 | 1 | 4 | 1 | 44334 |
| 1898_in_the_cage | 2 | 1 | 4 | 1 | 15643 |
| 1898_turn_of_the_screw | 3 | 0 | 9 | 1 | 18430 |
| 1902_some_short_stories | 0 | 1 | 1 | 0 | 18131 |
| 1902_wings_of_the_dove_vol_1 | 2 | 1 | 4 | 0 | 35262 |
| 1902_wings_of_the_dove_vol_2 | 2 | 0 | 9 | 1 | 45163 |
| 1903_the_ambassadors | 4 | 2 | 8 | 2 | 77633 |
| 1903_the_beast_in_the_jungle | 1 | 0 | 1 | 1 | 8198 |
| 1904_the_golden_bowl | 6 | 0 | 7 | 1 | 89794 |
| 1908_the_jolly_corner | 1 | 1 | 2 | 0 | 6737 |
| 1909_italian_hours | 4 | 1 | 19 | 1 | 65937 |
| 1916_notes_on_novelists | 4 | 1 | 11 | 4 | 65544 |
What’s nice about the solution provided by Zachary Wade Betz is that it’s quite easy to add data to the file that then gets fed into the table in the post. So, I haven’t looked at every single Henry James text—if there were more in the future, it would be easy enough to add those texts to a script and then let the computer take care of the rest, ultimately updating the table easily enough.
More to come, no doubt …
digital humanities TOML HUGO shortcodes turn of the screw HUGO tables word frequency counts work stuff python python for digital humanities
431 Words
2022-05-29 17:51