3 minutes
More The Turn of the Screw Data Analysis
I know I mentioned in an earlier post—and here—that I’ve been doing a bunch of work with Henry James’s canonical The Turn of the Screw. I thought I would post a little bit more here of what I’ve been up to as of late with this. A student of mine was fascinated by the use of the words “prodigious” and “portentous” in the Governess’s narrative in Turn. She said she noticed it frequently. It makes sense that these words would be in the Governess’s narrative, given her penchant for playing the detective (or the psychoanalyst), always trying to read the signs pointing to forbidden knowledge. But how often does she use these words? Let’s write some code, make some graphs, and figure it out.
First things first, let’s have a look-see at the NLTK library for some basic word counts/lexical dispersion plots.
A simple use of the nltk.text.concordance function can give us a nice print out of a specific range of tokens within the text that has the word in question.
import nltk
from nltk.tokenize import word_tokenize
from nltk.draw.dispersion import dispersion_plot
import matplotlib.pyplot as plt
with open(r'nltk_playground\tots.txt', encoding='utf-8') as f:
data = f.read()
tokens = word_tokenize(data)
tots_text = nltk.Text(tokens)
prodigious_concordance = tots_text.concordance('prodigious', width=200)
For “prodigious” we get the following output:

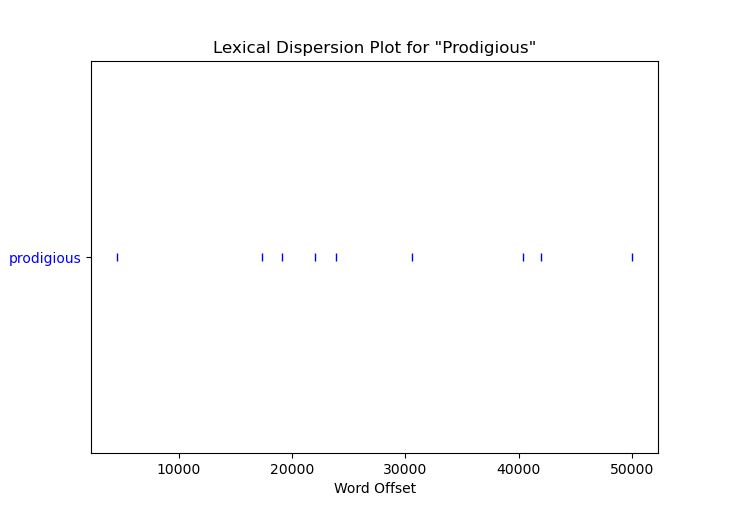
An equally simple call of the dispersion_plot NLTK function gives us an image of where the word appears in the text as a whole:
plt.figure(figsize=(12, 9))
targets = ['prodigious']
dispersion_plot(tokens, targets, ignore_case=True, title='Lexical Dispersion Plot for "Prodigious"')
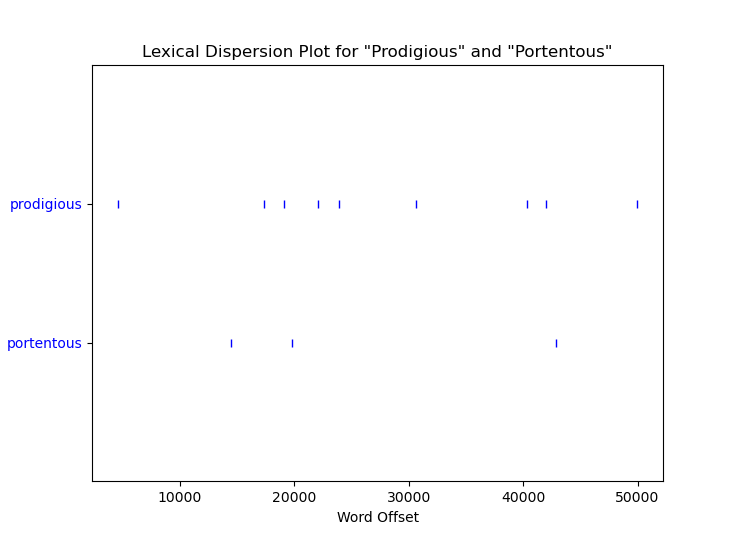
Of course, we can plot them both on the same figure if we like:
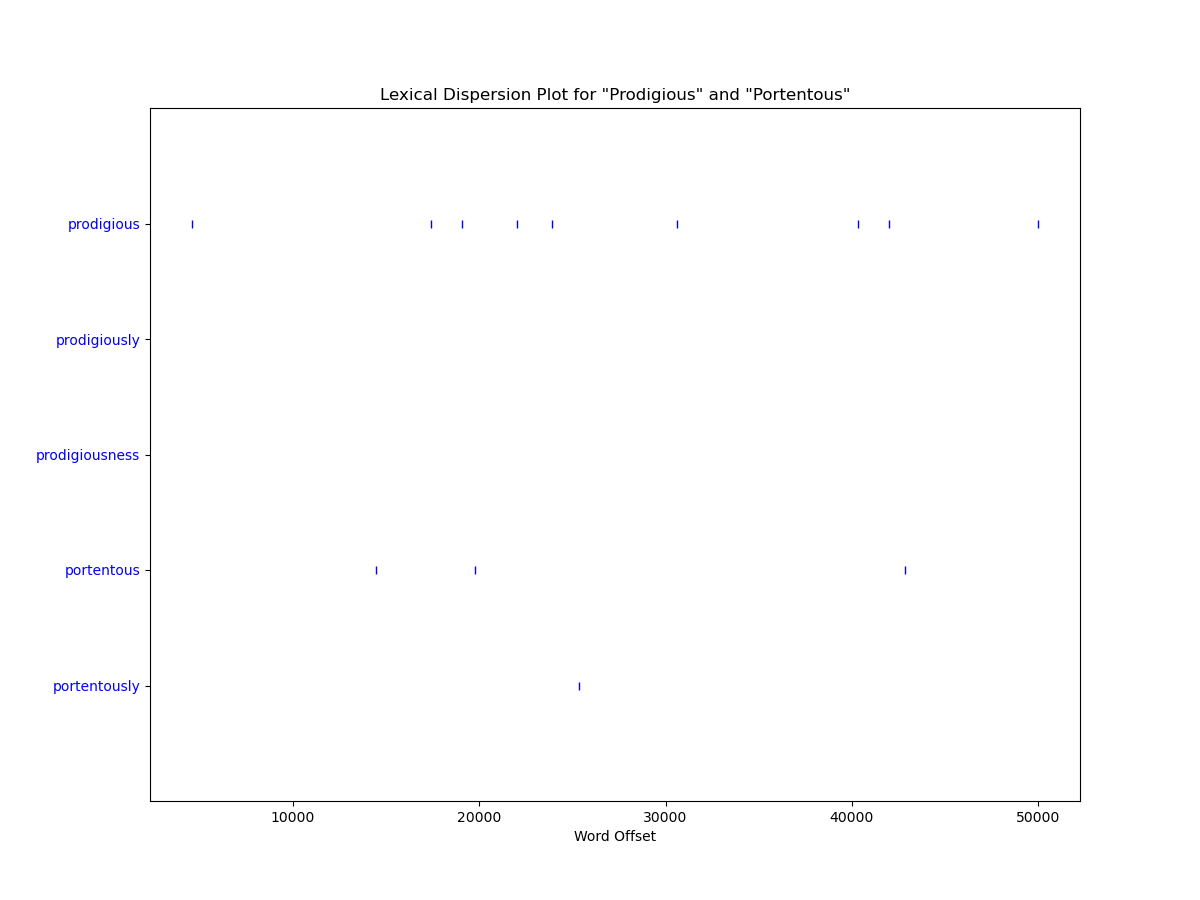
We could also lemmatize the text beforehand and see if we get any more words hitting our target list (here we’ll just provide a list of lemmas to search for, find, and then plot):
targets=['prodigious', 'prodigiously', 'prodigiousness', 'portentous', 'portentously']
dispersion_plot(tokens, targets, ignore_case=True, title='Lexical Dispersion Plot of Lemmas for "Prodigious" and "Portentous"')
After a bunch of conversations with my student about these words, I thought it might be curious to see how the frequency of these words compare over a larger selection of James’s corpus. Easy enough—I grabbed all the texts I could from Project Gutenberg by James. (A .json file with all of the counts of the target words per text is available directly from here.)
Again, some very simple Python code can give us counts of these words and lemmas across multiple works by James:
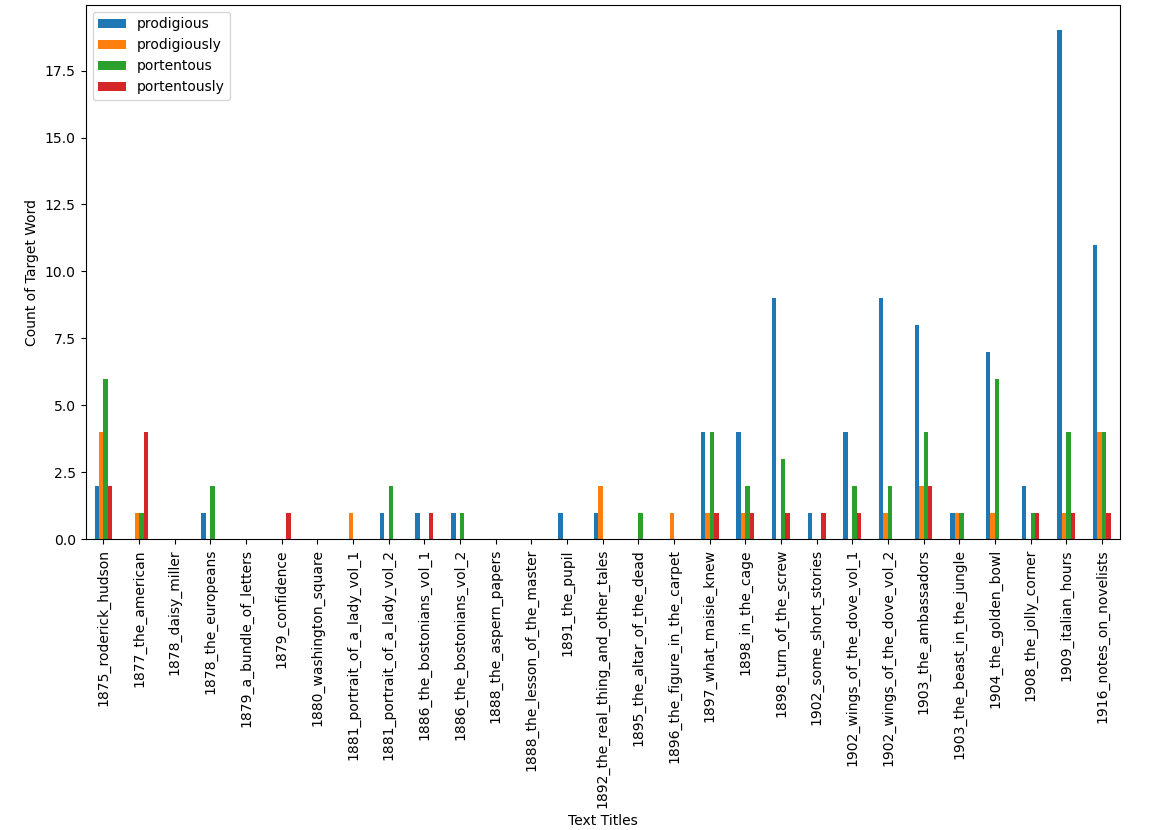
We can see that the frequency of some of these words go over the course of time; we also see that the counts for Turn are also pretty high, especially for “prodigious.” More to come on this, for sure, as I would like to write a post dealing with the motif of repetition in the story and a pretty simple and straightforward script to count repetitions of tokens over the entirety of the novella.
(All the code for this post is available in this repo.)
digital humanities henry james turn of the screw matplotlib nltk NLTK data visualization word frequency counts work stuff python python for digital humanities
482 Words
2022-05-27 11:49