4 minutes
Let’s Do Some Real World HTML Table Parsing with Beautiful Soup
Given that I’m continuing to chronicle my DH journeys here, I figured I’d showcase a little bit of my utilization of scraping data from a website with Beautiful Soup (docs are here).
Doing some research for a favorite student of mine, I’ve been wandering around websites devoted to law school. One website here has a really fantastic little table on the page that has everything one could want—especially if one is a little behind on deadlines and trying to catch up a bit (i.e. figuring out which schools will allow students to start in the Spring or Summer semesters [for an answer to that query, head over here]). Now, of course, one could just do the simple ol’ copy and paste of the table, but we all know how ornery things can get when one tries to paste it into Word or some other program and having to deal with all the formatting shenanigans—indeed, copy and pasting ends up with something like the following:
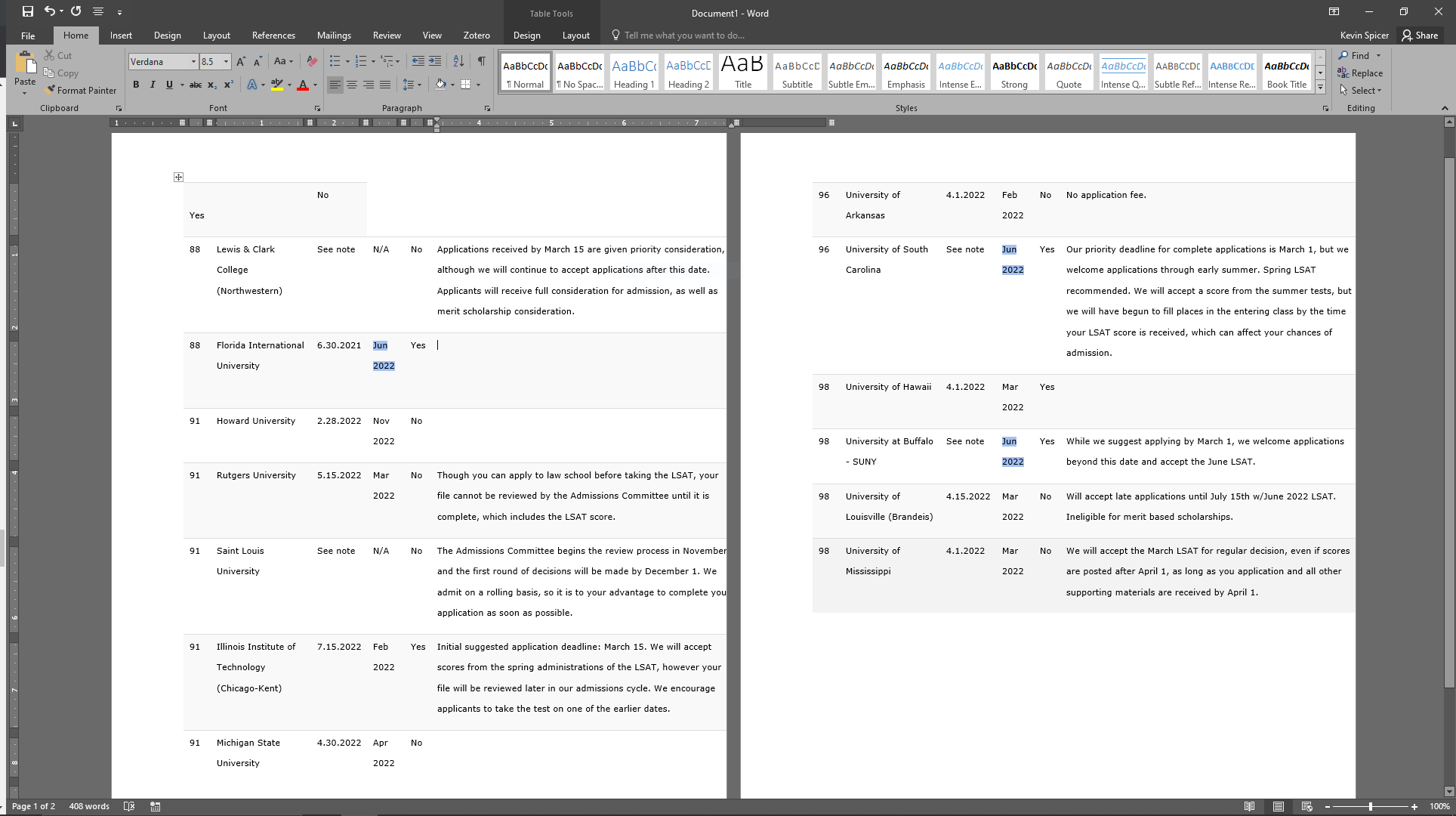
Rather than worry with that whole mess, why don’t we write a little code to get the thing into a nice format, maybe a simple Markdown table since the .md file extension seems to be my new best friend since getting into all this fantastically cool DH stuff?
First things we had a look at the html for the page, using the “View Page Source” function in Chrome after right-clicking on the page. Looking for a table id of some kind, sure, enough, here it is:

I also want to give a big shoutout to Thiago Santos Figueira’s very clear and simple Medium post on using Beautiful Soup to parse content in tables. His use case is a little bit complicated as it cleans up some of the numbers in the table in question there, so we can fiddle a little bit and grab only what we want. So for the script, we get all the required libraries imported along with some pandas customizations:
from bs4 import BeautifulSoup
import requests
import pandas as pd
pd. set_option('display.max_rows', 500)
pd. set_option('display.max_columns', 500)
pd. set_option('display.width', 1000)
Then we need to get the URL in along with the requests function to pull down the text from the URL and create a Beautiful Soup object:
url = "https://blog.powerscore.com/lsat/top-100-law-school-application-deadlines-2022-edition/"
data = requests.get(url).text
soup = BeautifulSoup(data, "html.parser")
We can then iterate through the returned text to get all of the tables on the page:
print('Classes of each table on the page:')
for table in soup.find_all('table'):
print(table.get('class'))
We know the table we’re interested in has a class of tablepress, so we store the information in a the table in a Python variable as follows:
tables = soup.find('table', class_ = 'tablepress')
We also have the column names in the table that we want to grab too, so we next create a DataFrame and pass in a list of column names matching those in the HTML table:
df = pd.DataFrame(columns=['2021 Rank',
'Law School Name',
'Application Deadline',
'Latest Acceptable LSAT',
'Accept the GRE?',
'Notes from the University',
'Difference from last cycle'])
Next we’ll fashion a for loop to run through the table, finding all the rows within the table (<tr>), grabbing all the information in the table’s body (<tbody>). We’ll also get all the columns in the HTML table matched up with our DataFrame column names:
for row in table.tbody.find_all('tr'):
columns = row.find_all('td')
if (columns != []):
school_rank = columns[0].text.strip()
school_name = columns[1].text.strip()
app_deadline = columns[2].text.strip()
latest_date = columns[3].text.strip()
gre = columns[4].text.strip()
notes = columns[5].text.strip()
difference_from_last_year = columns[6].text.strip()
df = df.append({
'2021 Rank': school_rank,
'Law School Name': school_name,
'Application Deadline': app_deadline,
'Latest Acceptable LSAT': latest_date,
'Accept the GRE?': gre,
'Notes from the University': notes,
'Difference from last cycle': difference_from_last_year}, ignore_index=True)
(For future versions of myself, pandas docs give a deprecation warning here for the pandas.DataFrame.append function [even more info here]; that said, the above works as of the writing of this post, so I’ve left it as is here.)
We can now set the index properly so we use the "2021 Rank" column as the index:
df = df.set_index("2021 Rank")
Then, if we would like to spit this out into a nice Markdown table, voila!
print(df.to_markdown())
And we have something super-easy to get into that fantastic .md extension. A fun little test case here. More to come, I’m sure, as always.
The repo with this really simple script is available here.
digital humanities digital rhetoric beautiful soup bs4 html tables html table parsing html parsing pandas DataFrame pandas DataFrame pd.to_markdown work stuff law school rankings real world applications real world implementations
724 Words
2022-05-25 00:05