6 minutes
More (Initial) Digital Humanities Stuff
I am totally not under the impression that any of these initial thoughts on my inchoate exploration of the DH field (a field whose history I am only now beginning to really grasp) will be of any use whatsoever. I am just beginning to dip my toes into water that others are already expert swimmers in—and have been for many many years.
I am not sure either if the kinds of things these digital or computational tools can do will be all they helpful to me in the long run. The literature is rife with the central question that no doubt is preeminent for most scholars in the humanities, especially those of us who cut our teeth on “close reading.” At the same time, learning about some of these new tools would seem to be fine give my recent (as of around July or August of last year) turn to a much more Deleuzian—rather than Derridean—philosophical posture and style of thinking. Why not use these tools to proliferate new and bizarre ways of thinking about what it is humanities scholars do? Why not take Nabokov’s Lolita and feed it through a bunch of algorithms designed for sentiment analysis? (Actually, I’m in the process of doing just that and it strikes me that Nabokov’s novel would seem to be one of those that should be a nice testing ground for all kinds of work in DH [and it could be already for all I know; as I say, I’m just barely getting a sense for what’s been done in the field so far, it’s all totally brand new to me). Even from the very first line of that novel Nabokov is playing with the very stuff of language—carving up into phonemes the name of the eponymous love interest of Humbert Humbert. I also noticed, just flipping through my copy recently, of what a morass Lolita could be for someone first training their (or their algorithm’s sights on it): the constant switch from English to French, the never-ending insertions of French phrases and names and dialogue, and—just staying within the language of English: Nabokov’s constant attention to and awareness of the phonetic stuff of language, e.g. take this from Part One:
… I kept repeating this automatic stuff and holding her under its special spell (spell because of the garbling), and all the while I was mortally afraid that some act of God might interrupt me, might remove the golden load in the sensation of which all my being seemed concentrated, and this anxiety forced me to work, for the first minute or so, more hastily than was consensual with deliberately modulated enjoyment. The stars that sparkled, and the cars that parkled, and the bars, and the barmen were presently taken over by her … (The Annotated Lolita, ed. Alfred Appel, Jr. [New York: McGraw-Hill Book Co., 1970], p. 61)
We all know what a distinguished polymath Nabokov was—and I wonder what DH methods of textual analysis and text mining such a text would be amenable to … As I say, I’ll get a cleaned-up version of the text ready and give it a go. (I should also probably give a shout out to David H— whose essay on Humbert’s aestheticism had been bouncing around in my head all week while over at Notre Dame; not sure why that was …) Why do I always feel this urge to never close a parenthesis like this—or at the very least to keep proliferating it indefinitely …?) What would a sentiment analysis algorithm do with all of H.P. Lovecraft’s fiction? Anything useful? (I’ll get on this one too and report back …)
As I say, it’s possible all these new tools are totally unhelpful, although I suspect that’s not going to end up being the case. Just one example to suffice for now. The South Bend DHRI sent along some reading materials to all the participants ahead of the institute. One little remark in Dennis Tenen’s article in Debates in the Digital Humanities, “Blunt Instrumentalism: On Tools and Methods” mentions the k-means clustering method in topic modeling as an algorithm that is non-deterministic, which means that it “will perform differently each time it is run …” Last academic year while working on the English Department’s Program Review I spent a great of time thinking about what it our faculty mean when they talk about “close reading.” I found myself returning again and again to talking about the ontology and philosophy of events, as that word is used (very differently) by Derrida and Deleuze. I found myself again and again running into this paradoxical situation where we describe the coming together of reader, text, and this third thing, the “event of reading,” which is absolutely singular and never to be repeated; simultaneously, this “event of reading” must be iterable, to use Derrida’s language. I think this idiom of non-deterministic algorithmic behavior could be helpful in giving me another way to describe what it is that we do when we closely read something. We do something algorithmic—we do not read arbitrarily, simply following our own whims and caprices—; there is a method to our madness, but it is not a deterministic one.
(Rereading some parts of Rita Felski’s The Limits of Critique for the NEH Summer Seminar I’ll be attending here very soon, I came across the following:
One indispensable link in this chain of mediators is a reader whose response is never entirely predictable or knowable. It is here that literary studies need to steer clear of a vulgar sociology (where a reader is reduced to the sum of her demographical data) as well as of a one-dimensional theory of language (where a reader is a nodal point through which language or discourse flows). Readers are not autonomous, self-contained, centers of meaning, but they are also not mere flotsam and jetsam tossed on the tides of social or linguistic forces that they are helpless to affect or comprehend. When they encounter texts, they do so in all their commonality and quirkiness; they mediate and in turn are mediated, in both predictable and perplexing ways. (The Limits of Critique [Chicago: U of Chicago P, 2015], p. 171.)
This is very nicely put—I dig it.)
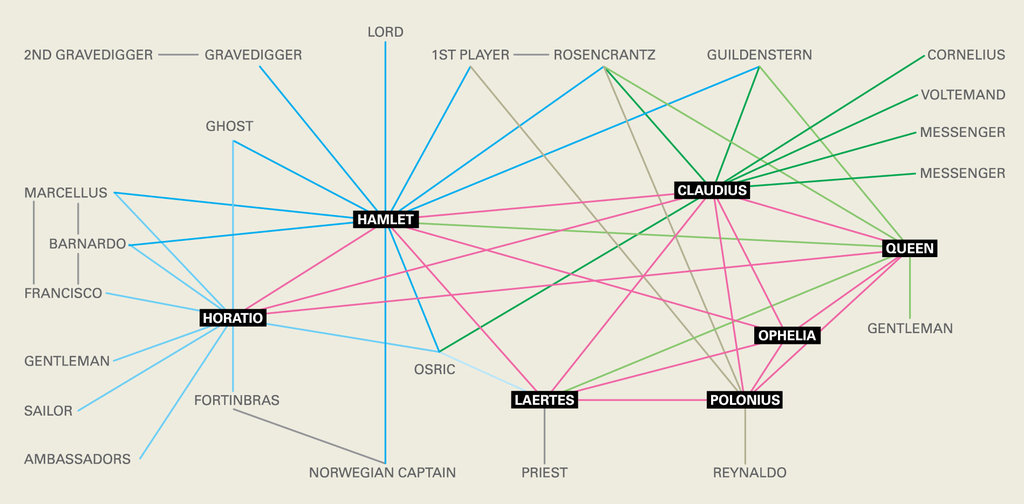
Fig. 1: Original Image from one of Franco Moretti’s Lit Lab papers, cited in Karen Schulz’s 2011 NYT article, “The Mechanic Muse”
The whole “close vs. distant” reading issue is no doubt just about gatekeeping, as Ted Underwood has argued, and is one of those things where my (re)turn to Deleuze is helpful: a logic of opposition should not be chosen over a language of difference—distant reading is perhaps just simply a different way of reading and not necessarily opposed to reading closely. An unsupervised (or supervised) nondeterministic algorithm is what we do when we humans read closely? Why not?
P.S. Next on my reading list is Wendy Nelson Espeland and Mitchell L. Steven’s 2008 essay, “A Sociology of Quantification” and Katherine Bode’s essay in MLQ, “The Equivalence of ‘Close’ and ‘Distant’ Reading; or, Toward a New Object for Data-Rich Literary History.”
1180 Words
2019-07-06 18:05 (Last updated: 2021-12-24 15:19)